探究 DDD 在前端开发中的应用(二):什么是 DDD
DDD 简介
DDD 是英文 Domain-Driven Design 的缩写(不是 DDL Driven Development),中文译名为领域驱动设计,诞生于本世纪初。它为人们提供了战略和战术上的建模工具,帮助人们准确把握业务需求,产生精准的建模设计,进而高效率地设计、维护软件。
对于在软件开发领域中缺乏经验的许多大学生来说,DDD 更是提供了让他们看待代码的另一双眼睛,这双眼睛不仅能看到他们写出的每一行代码,还能看到在这些代码之上形成的结构,启发他们思考代码与代码之间的关系,进而让他们对架构形成一定的认识。如果说《C Primer Plus》、《C++ Primer》这些书籍能教你成为一名士兵,那么 DDD 这样的建模工具则能教你成为一名战略指挥官。
受篇幅限制,我们接下来只能对 DDD 的基础概念进行简要的介绍,如果你有时间,请阅读关于 DDD 的经典书籍《实现领域驱动设计》。
通用语言与限界上下文
DDD 作为一个建模工具箱,当然是为了建模而生的。简单来说,DDD 是使用通用语言(Ubiquitous Language)区分出的限界上下文(Bounded Context)来对需求的子域(Sub-domain)进行建模的工具箱。
通用语言是一些单词或者短语的特殊含义,或者开发团队之间形成的各种约定。通用语言是既描述了业务需求,又在代码设计中得到体现。限界上下文则是一个语义和语境上的边界,其中的每个代表软件模型的组件都有着特定的含义,并且处理特定的事务。这里界定所谓“特定”的概念就是通用语言。
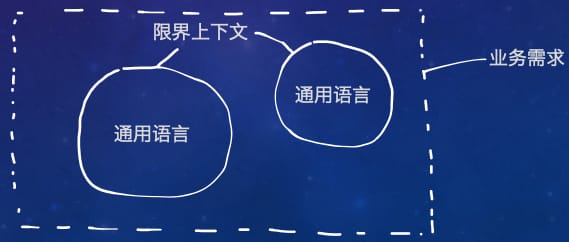
在大型项目中,一个限界上下文往往对应一个由程序员、领域专家和产品经理等角色构成的开发团队。团队成员之间会在工作交流中使用这种通用语言,并且程序员书写出的软件模型的源代码就是通用语言的书面表达方式。因此,限界上下文和通用语言既是软件结构层面的设计,还是团队结构的设计,这一点和康威定律(Convey's Law)不谋而合。
负责两个限界上下文的人员的办公室里传出来的语言是明显不同的
要进一步理解通用语言和限界上下文,我们不妨从它们的反面出发:在整个软件中随意使用语言,不划分任何模块。这样做会有什么后果呢?随意使用语言会提升开发团队的沟通成本,还可能导致误解的出现,甚至会导致产出的代码中产生严重的 Bug,或者偏离产品经理的预期。
例如在某个计分系统中,计分板代码中使用了 grade 这个词语来表示一个具体的分数,使用了 score()来表示教师的计分动作。然而,在计分板数据库代码中,使用了 score 来表示具体的分数。这样的结果就是,接手这些代码的程序员需要提高警惕以免混淆两边的 score,造成了注意力的浪费,并且在大规模的代码库中,长年累月的修改会使得两个 score 杂糅在代码中,留下了更大的隐患。
不严格划分模块,意味着负责不同功能的代码会在多次修改之后变得亲密无间,难分你我。这种行为或许在软件开发的初期有着较高的效率,但当软件开发进入维护阶段时,则会给维护软件的程序员带来噩梦,因为不同行为的代码混合在同一个文件夹甚至是同一个文件,导致程序员在下手修改某个行为前都需要仔细辨析相关的代码,甚至在修改后都在提心吊胆,生怕修改的代码会影响到其他功能的正常运行。

对付这样的代码就如同抽积木一般危险!
DDD 建模过程
从上文可以总结出,通用语言和限界上下文是相辅相成的关系。在开发的早期,面对给定的需求,开发团队会在头脑风暴时识别出一些存在差异的通用语言,然后将这些语言对应的组件划分给一个限界上下文。在开发过程中,甚至到了软件的维护阶段,限界上下文的发展又会反哺通用语言的进一步精细化、严谨化。
让我们先了解一下 DDD 建模的第一个步骤:开发团队首先进行讨论,发掘业务需求的全貌。然后开发团队会根据通用语言的不同划分出不同的子域,在不同子域中继续发展通用语言,让它们变得更精确严谨,使这个子域成为限界上下文。
开发团队中必须含有领域专家(Domain Expert)和软件开发人员。与软件开发人员关注于技术不同,领域专家更加关注实际的业务问题,他们会更多的从宏观角度分析业务需求,调动开发团队进行融洽的合作。他们非常了解如何进行领域设计来让公司的业务更上一层楼。
领域专家的存在使得软件开发人员不会在发展通用语言的过程中使其偏离实际的业务,导致整个项目充满了程序员间才懂得的语言,产品经理和程序员间出现沟通障碍等问题。因为领域专家有着和软件开发人员不一样的心智模型。DDD 中尤其强调拥抱业务需求本身,而尽量克制程序员“以技术为中心”的冲动。因此,软件开发人员需要和领域专家亲密合作,共同发展通用语言。

开发人员和领域专家所思考的事务往往是不同层面的
DDD 建模过程实例
让我们用一个实际一些的例子来说明这个过程,这个例子将在之后介绍 DDD 继续使用:假如有一个叫做 Vatrix 的课程平台被某公司正式立项,这个课程平台以课程为基础,提供程序设计作业的布置和在线评测功能。现在,假设我们是开发团队的一份子,让我们走进 Vatrix 开发团队的会议室中,参与 Vatrix 的头脑风暴!Vatrix 开发团队的需求分析会议正式开始,有请领域专家、程序员、产品经理等人进场。小明端庄地掏出粉色笔记本,向大家展示了它给出的领域设计草稿。团队成员们开始围绕业务需求进行探讨。
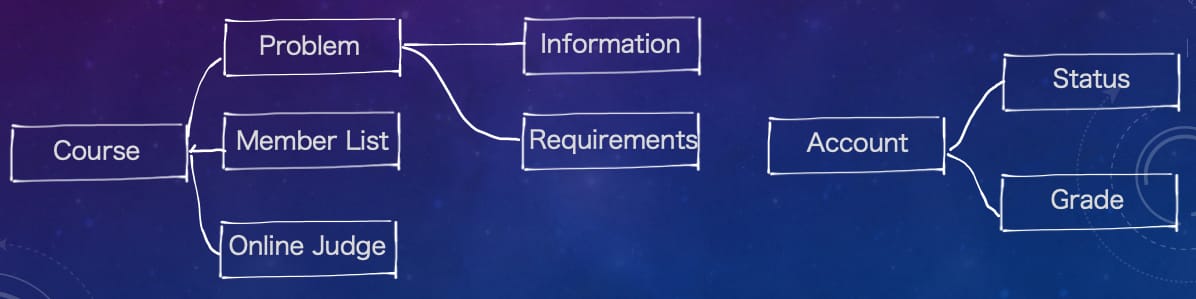
有人提出:课程平台应该来一个讨论区,让老师和同学之间可以对题目进行讨论。队员们普遍表示认同,于是平台的领域结构图被扩展了。其中的命名是领域专家和软件开发人员们共同商定的。
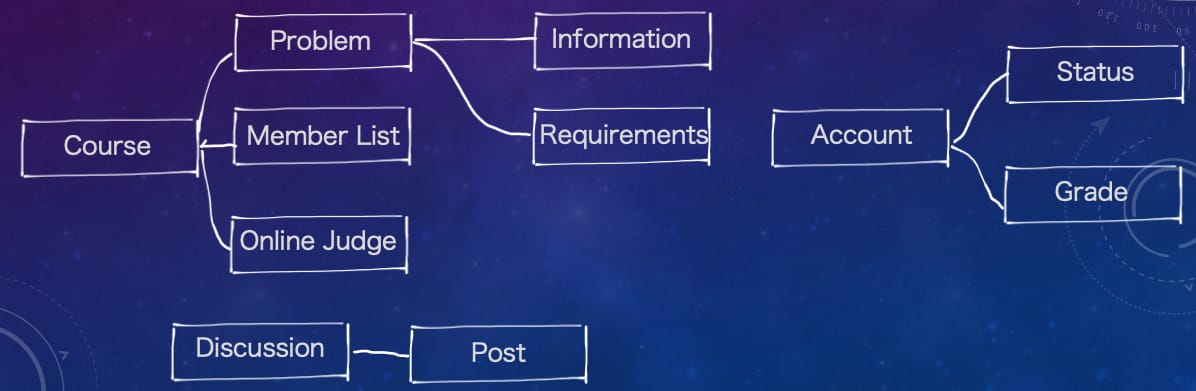
不一会,又有人跳起来说:咱们是不是忘记了一件重要的东西?我们应该提供一个题库功能供老师们创建和套用到课程中!扩展之后的设计图大家都很满意,于是 DDD 建模进入下一个阶段。
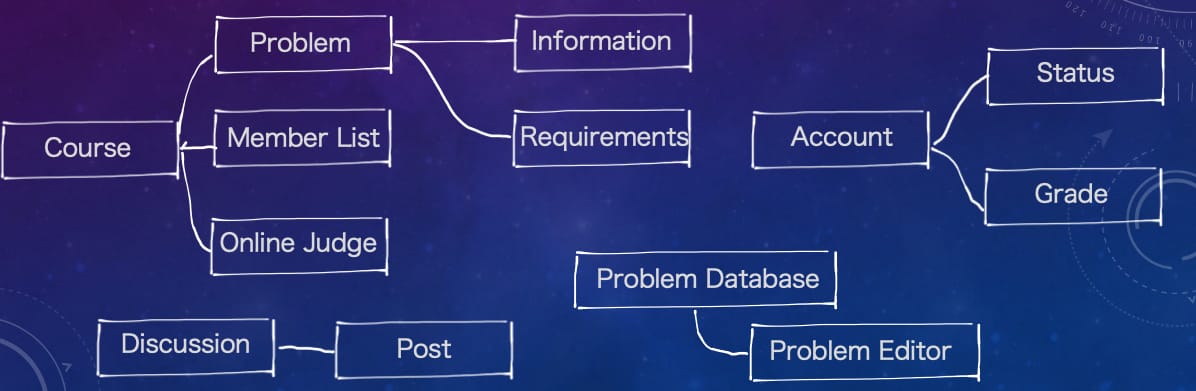
此时领域专家上台,将设计图按照通用语言的差异划分出了以下的子域。然后,开发团队将分为四组,各负责一个子域。工作开始后,小组内部会经过多次开发讨论,持续地为了实现业务需求发展子域的通用语言,限界上下文逐渐形成。发展通用语言的方式包括但不局限于:What-Why-How、Use Case、User Story 等,由于篇幅有限这里不作展开。
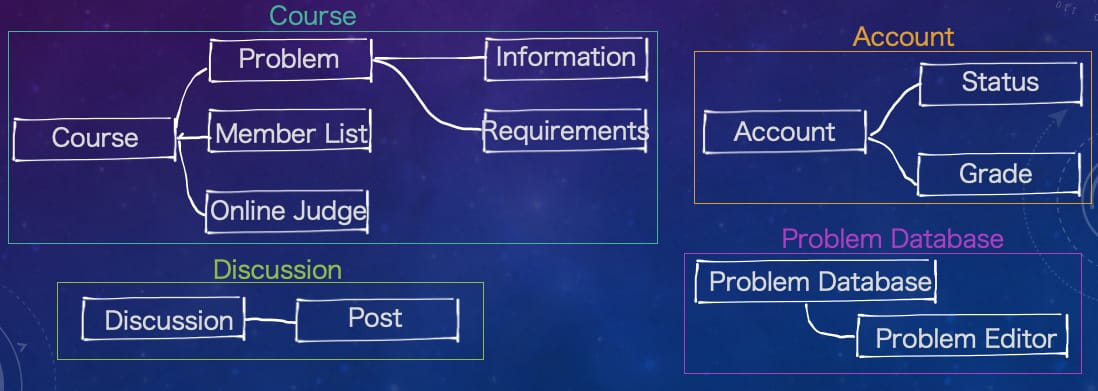
上下文映射
当限界上下文被发展出来之后,DDD 项目的核心域需要和其他限界上下文进行集成,这就是 DDD 的上下文映射(Context Mapping)。如果没有集成,那么我们的团队最后开发出来的成品只是四个孤立的组件而已,只有经过集成才能将它们连接到一起,成为一个能够正常工作的软件。例如,Course 限界上下文需要集成 Problem Database 限界上下文来实现业务需求中的出题功能。
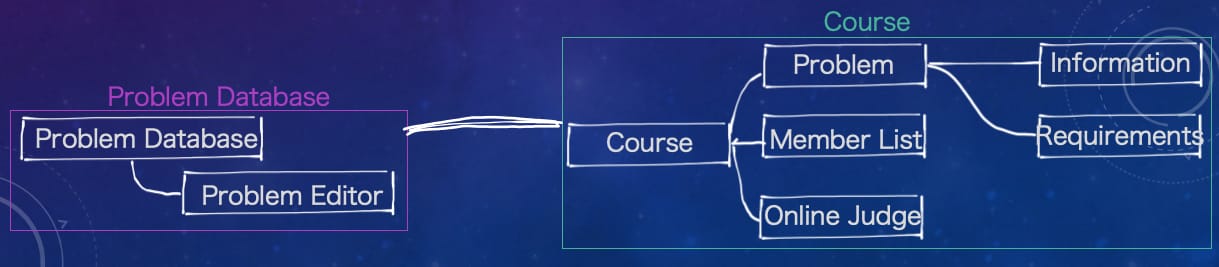
上下文映射不仅表示了两个限界上下文的集成关系,还表示了两个团队之间的动态关系。由于不同的限界上下文的通用语言差异较大,因此团队之间处理上下文映射时尤其应当注意克服通用语言差异的鸿沟带来的潜在问题。两个团队之间存在的动态关系可能表现为以下的其中一种:合作关系(Partnership)、共享内核(Shared Kernel)、跟随者(Conformist)、开放主机服务(Open Host Service)。由于篇幅原因只列举了最常见的几种。
上下文映射的关系
合作关系是指两个限界上下文的团队之间具有一些重合度较高的目标以及实现思路。这样的团队会对开发进程的同步有较高的要求,因此经常会需要开会沟通,协同进度。
共享内核是指两个团队之间通过共享一个小规模但通用的模型来实现限界上下文的集成。例如负责资源监控限界上下文的团队要求负责邮件发送限界上下文的团队共享一个发布邮件的模型,来让前者能够在资源监控出现问题时发布邮件通知用户。
跟随者模式是指,当一个团队需要集成一个已经存在且规模庞大的限界上下文时(通常发生在下游团队和上游团队之间),下游团队无力翻译上游上下文的通用语言,而只能直接套用上游上下文的组件,因此下游团队成为了上游团队的追随者。例如我们在开发微信小程序时必须顺应微信团队的各种约定和要求。
开放主机服务是指团队定义一套协议或者接口,让自己的限界上下文可以作为一个服务让其他团队集成。这样的团队往往会提供一套详细的文档方便其他团队的开发。例如 Twitter 提供的公开 RESTful API 可以让每个开发者向自己的软件中集成 Twitter 的某些功能。
聚合
现在,让我们进入限界上下文内部,看看 DDD 为限界上下文内部的设计提供了什么样的工具。首先值得介绍的就是聚合(Aggregate)的概念。它指的是限界上下文中一个个的代码集合体,由实体或值对象构成,其中有一个处于根节点的实体被称为聚合根(Aggregate Root)。聚合根控制着所有聚集在其中的其他元素,并且它的名称就是整个聚合的名称。一个限界上下文可以存在多个聚合,下面只列出了一个。
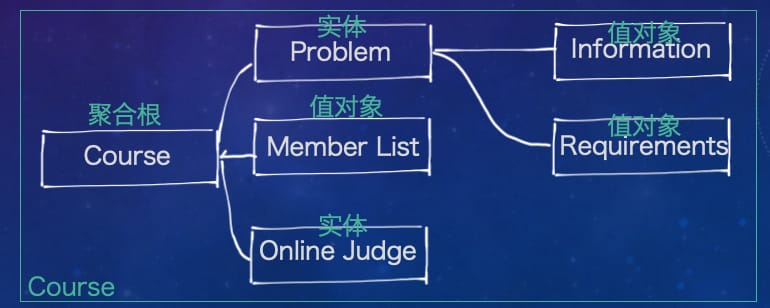
从聚合开始,DDD 将触角伸向微观层面,指导我们如何结合系统分析,对每一个类进行设计。聚合中有一个非常重要的概念:每个聚合是事务一致性的边界。 所谓事务一致性,指的是在一个聚合中,所有被提交到数据库的事务执行后,整个聚合的所有组成部分必须严格符合业务规则。事务一致性的确定需要开发团队紧密结合业务需求来确定聚合何时处于有效状态,以防止破坏业务的操作发生。
看上去,这和数据库概念中的完整性约束、谓词约束等有相似之处,后者对数据表中的实体取值按照维护者的意愿进行限制。事实上,数据库的这些约束手段可以作为实现聚合的事务一致性的手段之一。不过,需要注意聚合的事务一致性更加强调:只能在一次事务中修改一个聚合实例并提交。
聚合的事务一致性约束开发团队在设计聚合时必须紧密结合业务需求,按照让聚合维持一致性和提交成功的方式来进行。这呼应了开头的那句话:“设计并不仅仅是感观,设计也是产品的工作方式。”此外应该注意,聚合的事务一致性必须由业务规则驱动,而不应该由技术驱动,否则我们将背离 DDD 的初衷。 这里列举一些设计聚合时值得参考的几条原则:
- 在聚合边界内保护业务规则的不变性。
- 聚合应该设计得小巧。
- 只能通过标识符引用其他聚合,而不是对象引用之类的。
- 使用最终一致性更新其他聚合。
领域事件
四条原则中的最后一条“使用最终一致性更新其他聚合”应该如何实现呢?例如,假设一位学生用户在 Vatrix 中加入了某个课程,那么 Account 限界上下文中的 Account 聚合应该提交对「已加入课程」的更新,但这只维护了这个聚合内部的事务一致性,我们还需要维护课程限界上下文中的成员列表聚合,向其中加入这位学生的学号才算是完成了业务需求的「学生可以加入课程」这一项功能。
这种对聚合之间最终一致性的需求催生了领域事件(Domain Event)的概念。它是一个聚合发布的、由利益相关的限界上下文订阅的事件,通常经由消息机制以发布/订阅的方式实现。下面我们结合上面的例子看一个图例。
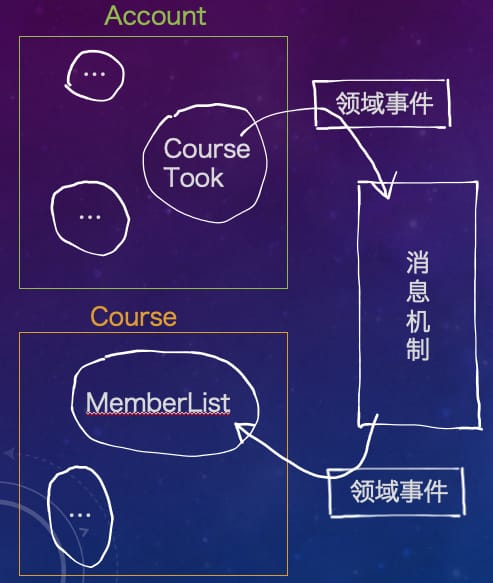
如上图所示,CourseTook 聚合通过发布 StudentTookCourseEvent 这样一个领域事件到消息机制中,然后对此感兴趣的 MemberList 聚合将接受这个事件,并作出反应。它会从事件中读取到对应的学生学号,并将它加入到课程的成员列表中,最终一致性由此实现。
需要强调的是,领域事件在维护聚合一致性中如此重要,以至于它的任何接受者都必须贯彻落实相应的动作,不得因为任何原因放弃执行。同时领域事件的发布和传递必须高度可靠。
保障领域事件正确运行
无论是使用 MQ 还是其他方式实现承载领域事件的消息机制,必须强调的议题是消息机制的可靠性。当服务器机房的天花板漏水,或者是空调出现故障导致服务器,又或者是中大的施工队再次挖断电缆,导致服务器不得不中断运作时,我们当然不希望那些仍在传播中的领域事件消失,破坏系统的最终一致性。
因此,应该对各种领域事件进行有效的持久化处理,这同时也能作为一种聚合实例发生变更的历史记录,从而我们不仅能在意外出现时重建聚合,还能拥有一定的溯源能力,提高系统的可靠程度。
聚合的实现例子
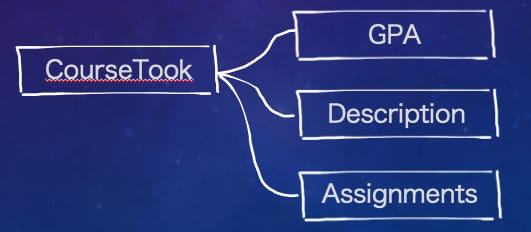
下面让我们通过一段代码来实现上面所说的 CourseTook 聚合,假设它的构成如下图所示,其中 GPA 和 Description 是值对象,Assignments 是实体。我们的第一步是实现聚合的根节点 CourseTook 对应的类。然后再实现聚合根下的各种实体。
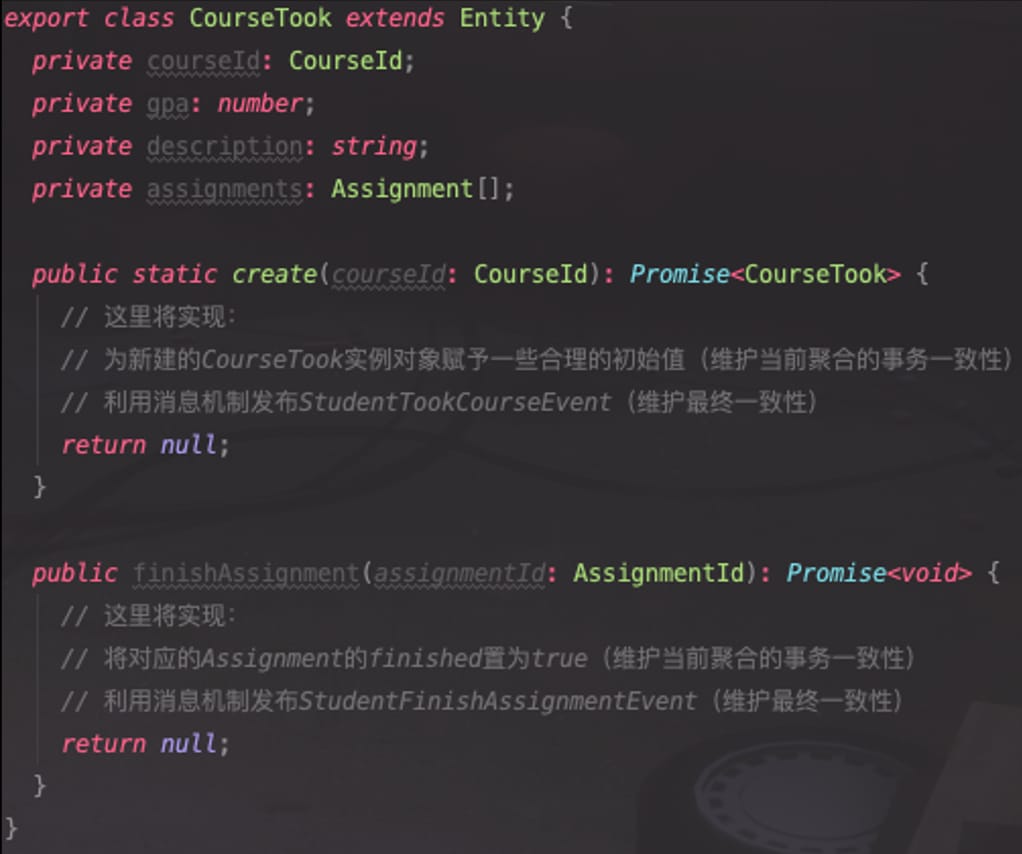
具体的实现请看本人写的一段 TypeScript 代码。请注意这样的一个类是如何拥抱业务需求,封装业务逻辑的。其中,聚合的实体类一般都会继承一个公共的基类 Entity,这个基类一般会负责维护唯一的实体 ID、比较逻辑,以及为子类提供发布领域事件的 API 等。
像这样设计聚合之后,我们的路由处理的逻辑将被大大简化,请看下面的 NestJS 的一段代码。
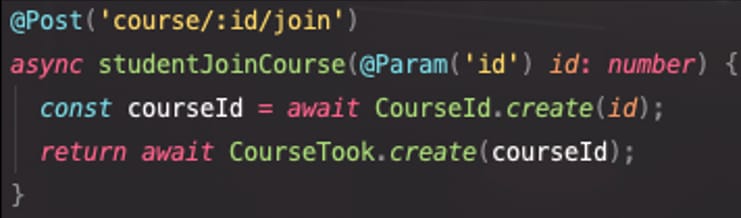
与那些直接将业务逻辑写在路由处理方法中的传统做法不同,我们将业务逻辑全部地保留到了实体本身中,而路由处理方法仅负责组装响应。这种做法与 DDD 中以业务需求为本的思想相统一,实体类中既封装数据,也含有业务需求中对数据做出的约束。这也使得业务逻辑与访问方式脱钩,也就是说,不仅是像上面的 RESTful API 可以复用实体创建逻辑,像 GraphQL 的 Resolver 也可以直接复用。
DDD 的整体架构
聚合的实现例子反映出了 DDD 不同的代码架构,请看下面的对比图。
在 DDD 中,Domain 层位于最核心的位置,并且有着一个严格的依赖规则:外层可以依赖内层,但内层不能依赖外层。这就是为什么 Domain 层需要通过领域事件去发布事件的原因。
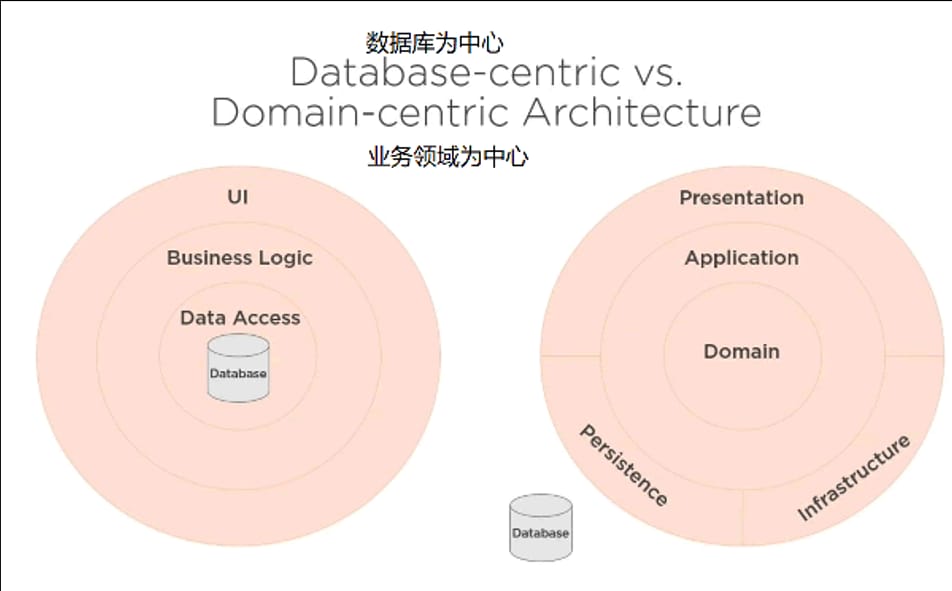
来自 https://www.jdon.com/ddd.html 的图片
小结
对 DDD 的基础概念介绍总算是告一段落了。遗憾的是由于篇幅原因,DDD 中还有许多经典的概念并没有纳入讨论范围。如果你有兴趣,推荐你阅读 Vaughn Vernon 写的《领域驱动设计精粹》和《实现领域驱动设计》。
本节内容的参考:
- https://www.jdon.com/ddd.html
- 《领域驱动设计精粹》(作者 Vaughn Vernon)