DeepSearch 技术沙龙参会笔记与个人思考
前言
本周六,我参加了由 Jina AI 和 Google Cloud 联合主办的 DeepSearch 技术沙龙的深圳场,这是该系列技术沙龙的最后一场,前两场分别在北京、上海举行。这场技术沙龙的内容主要由下面的三个部分构成,其中第一和第三部分由 Jina AI 的 CEO 肖涵先生分享。
- 回顾 Jina AI 自 2024 年以来的工作成果,包括发表的论文、AI 模型等。
- Google Cloud 上的 AI 产品介绍,包括炙手可热的 Gemini 2.5 Pro等。
- Jina AI Deep Search 的实现原理。
深圳场的技术沙龙在 Google 位于深业上城的办公室举行,我从南山打车过去要半小时,差点晕车。本文记录了我在参会过程中做的笔记以及一些思考。本文的黑底图片均截取自 Jina AI 的 PPT 和博客文章。

会议室楼层的前台,笔筒里的好几只笔都是坏的

肖涵先生作开幕致辞

Google 的甜点确实非常好吃
语义搜索
根据肖涵先生介绍,Jina AI 目前聚焦于 AI 搜索的基础研究,包括基于 Transformer 架构的基础模型。会上围绕「语义搜索」介绍了下面的两种模型:
-
Embedding 模型:将输入嵌入到一个向量中
Jina AI 最新的 Embedding 模型主要是 jina-clip-v2 和 jina-embedding-v3,前者支持文字和图像输入;后者拥有 SOTA 性能,但只支持文字输入。
肖涵先生特别提到,jina-embedding-v3 模型支持「跨语言」嵌入,能够用一种语言搜索另一种语言的内容,而其它一些声称支持多语言的模型往往只能用同一种语言搜索相同语言的内容。此外,此模型还支持多种搜索模式,特别是「非对称搜索」和「对称搜索」,前者能够依据疑问句等自然语言的语义查询目标文档,后者则根据文字的相似度进行查询。
-
Reranker 模型:将输入逐字和给定文档进行对比,计算相似度排名
Jina AI 最新的 Reranker 模型是这个月刚发布的 jina-reranker-m0。

上述两种模型工作方式的对比
Jina AI 认为,语义搜索可以由下面的三个流程构成:
- 粗搜索:基于简单的关键词匹配和 BM25 等算法快速匹配,快速确定一个较大的候选文档范围
- Embedding:基于 Embedding 模型,计算搜索词和候选文档粗略的相似度,缩小候选文档范围
- Reranker:基于 Reranker 模型,逐字对搜索词和候选文档内容计算相似度,按相似度从高到低的顺序给出最终的候选文档排名
这三个流程预期会将候选的若干篇文档进行逐步筛选并得到数量极少但准确度极高的结果。其中,Embedding 步骤是可选的,关键是要平衡算力需求和用户体验。Jina AI 称 Reranker 模型的效果一定比 Embedding 模型好,因为从原理上看前者是逐字比较,后者是先压缩到一个向量再比较,但前者要求的计算量显著更高。如果第一步给出的候选文档数量相对较少,那么可以直接进行 Reranker 步骤。
后期分块(Late Chunking)
关于 Late Chunking 的细节可以阅读 Jina AI 的博客。
很多情况下,我们不得不将文档切片成若干片段之后再进行语义搜索,例如原文档字数超出模型的上下文窗口,又如将整个长文档压缩为单个向量可能导致一些重要的信息被稀释。当前主流的方式寻找一些分割点对原文档进行分割(Chunking),再将分割后的文档块单独计算嵌入向量。确定分割点的方式五花八门,包括机械式的(按句子、段落切分)、基于大语言模型的等。
不过,这种方式很容易导致上下文的缺失,例如将一些需要连在一起读才有完整意义的段落进行分割后,搜索只召回了其中一个片段,导致无论是大模型还是人都读不懂。考虑一个极端情况:一篇文章只有第一段介绍了某个名词的含义,剩余的片段全部只使用「它」来指代这个名词,这会导致用户在使用这个名词搜索时,系统难以召回其它段的内容。
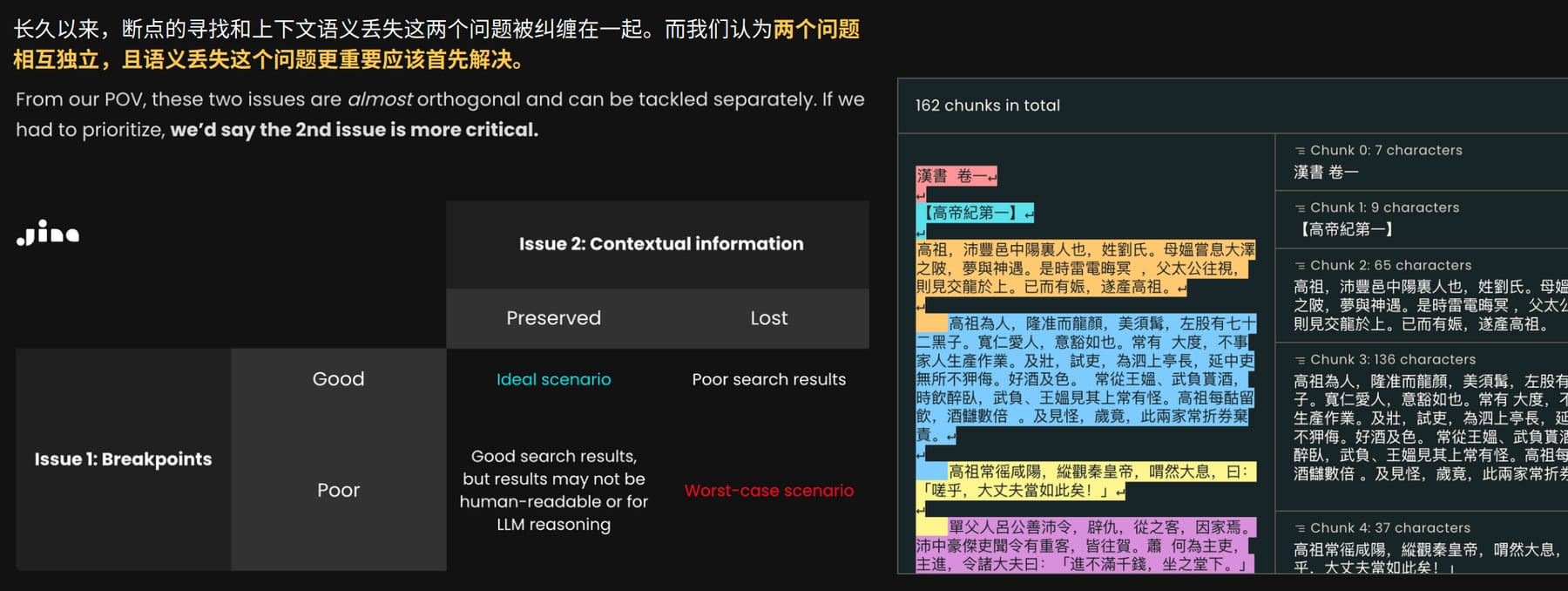
当前主流的 Chunking 方式存在的问题
Jina AI 给出了一个原理相当简单的解决方法:先将原文档的所有内容嵌入,之后再做分割,这就是 Late Chunking 技术。将原文档的所有内容嵌入可以对每个 token 都得到一个向量,即使后续文档内容被分割,我们仍然能够依据向量中隐含的上下文信息召回相关的片段,缓解上述极端情况中的问题。此外,肖涵先生强调 Late Chunking 机制在召回内容的可读性和相关性之间选择了后者,因为其结果主要是呈现给大模型的,后者对内容的相关性更为敏感。
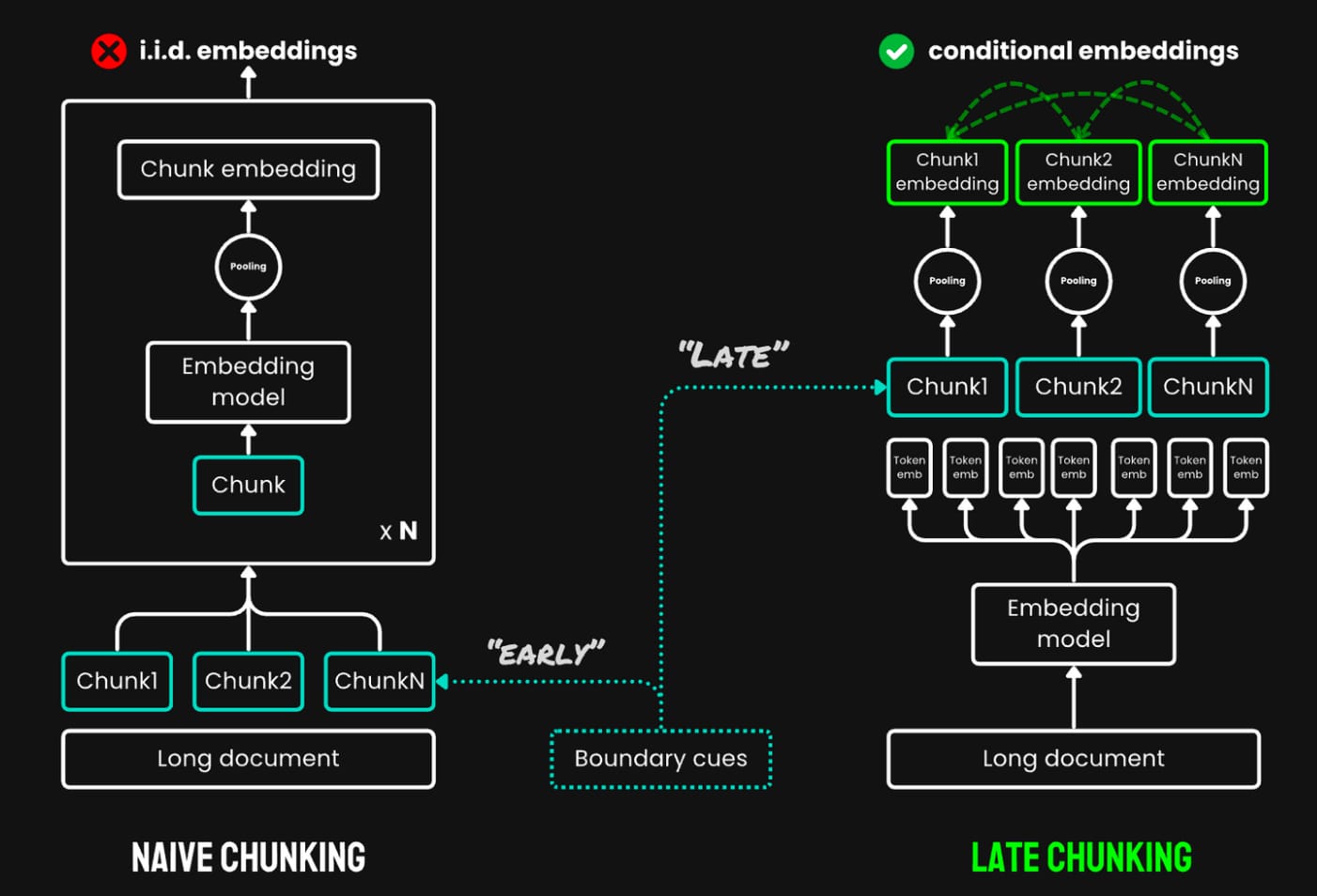
Late Chunking 的原理及对比
Jina Reader
除了 Embedding 模型和 Reranker 模型,Jina AI 还在 decoder-only 模型上进行了探索。Jina AI 的 Reader API 能够读取 HTML 网页内容并输出适合大语言模型理解的 Markdown 文字,优化大模型的搜索表现。
肖涵先生表示,Reader API 最初是使用正则表达式和各种工具库实现的,后来切换到使用大模型端到端地完成,在各种边界场景中拥有更好的表现。最新的 ReaderLM-v2 模型的参数量仅为 1.54B,具有高达 512K 的输入窗口。
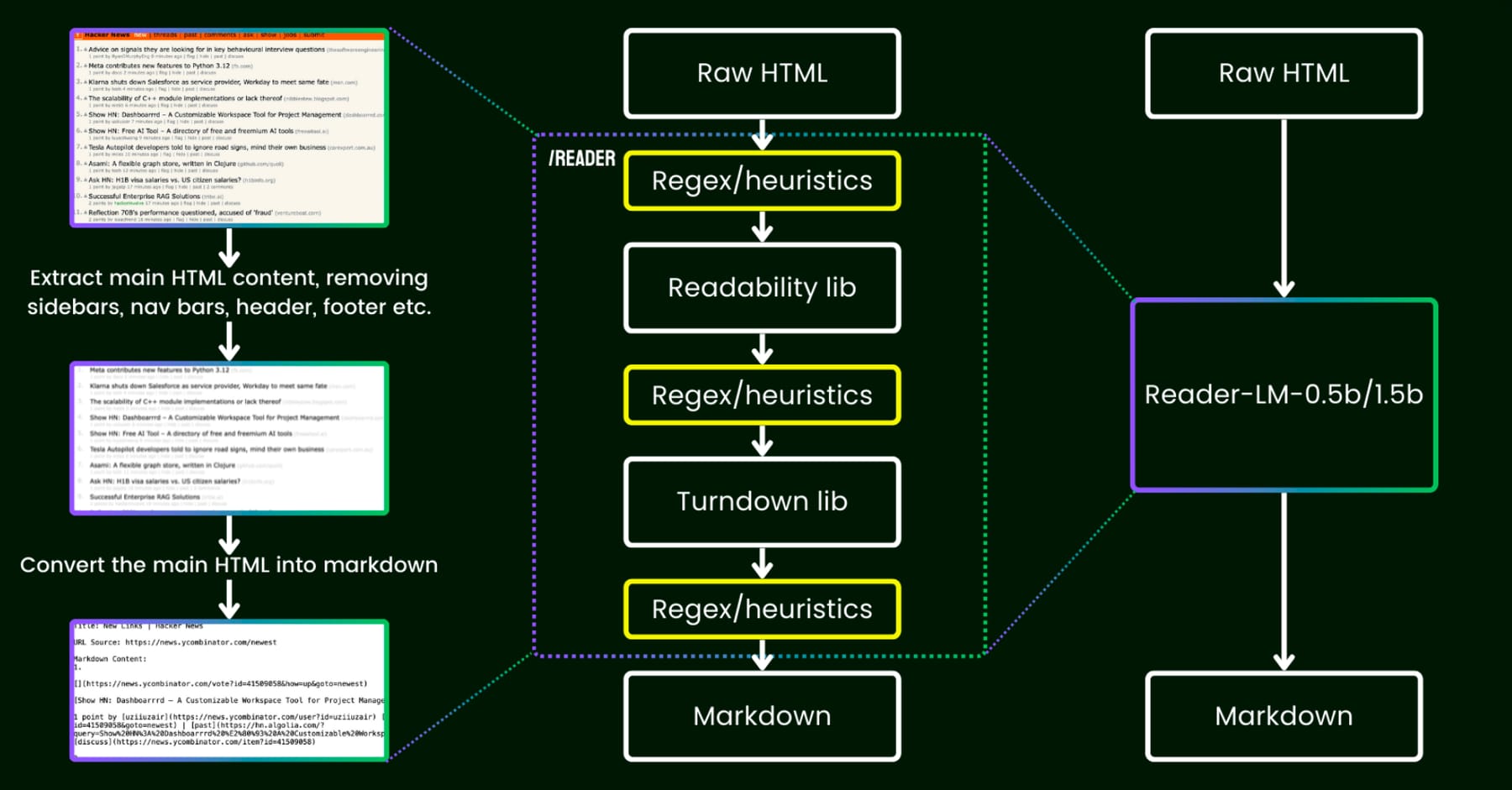
Reader API 新旧架构的对比图
未来发展
会上有人向肖涵先生提了一个很好的问题:当前大模型的上下文窗口越来越大,已经到达 1M 的级别,这是否表示 Embedding 模型和 Reranker 模型的重要性会不断降低?肖涵先生的回答大致是:Embedding 模型和 Reranker 模型在未来会更多地在大模型自己的上下文中(所谓的「in-context」)工作,比如上下文压缩等场景。像过去那样从搜索引擎的数据库中拉取数据的用法可能会越来越少。
深度搜索(Deep Search)
在 Jina AI 的定义中,深度搜索(Deep Search)指的是大语言模型通过多次的搜索(search)和浏览(browse)获取回答问题所需的知识,深度研究(Deep Research)指的是大语言模型在深度搜索的基础上形成一篇内容有深度且长度较长的研究报告。
对于深度搜索,Jina AI 提出了基于 While Loop 的实现方式,如下图所示。「搜」指的是能够获得 SERP 的搜索,比如 Google Search 的结果页,仅包含网页的标题、链接和一小段相关文字。「读」指的是浏览网页内容,如使用 Jina Reader 获取 Markdown 格式的网页内容。

Jina AI 的深度搜索运行流程
这种类似工作流的实现方式和我过去的想法有很大出入。我先前认为在 DeepSeek R1 和 OpenAI Deep Research 推出之后,无论是研究者和开发者都应该将精力集中在依靠模型自己的智力端到端地解决问题,而不是依据人的经验来设置一些固定的流程,这样才能最大限度地发挥当前思考模型的潜力,以及在像 Deep Search 这类边界情况极多的场景上获得更好的泛化能力。我会在后文继续讨论这个话题。
搜索词生成
在「搜」这一步中,Jina AI 额外做了搜索词的生成,由语义扩展和去重两个步骤构成。语义扩展将用户以自然语言表达的搜索词扩展成类似 BM25 的关键词,以期望搜索到更多的跨语言和内容格式的潜在答案。我认为,语义扩展除了将搜索词进行形式的转化之外,最重要的是完成了对用户需求的发掘(尽管这种发掘是通过用大语言模型进行猜测得到的)。
你可以在这里找到语义扩展的相关源代码和提示词。

语义扩展的例子
去重步骤会将语义扩展得到的若干搜索词进行比较去重,比较的对象是迄今为止搜索过的所有搜索词,这样可以避免大语言模型浏览到过去浏览过的网页。去重使用的是前文提到的 jina-embedding-v3 模型,Jina AI 在博客中给出了理由:
对于查询去重,我们最初使用了基于 LLM 的解决方案,但发现很难控制相似度阈值。我们最终转向了 jina-embeddings-v3,它在语义文本相似性任务上表现出色。这使得跨语言去重成为可能,而不用担心非英语查询会被过滤。embedding 模型最终成为了关键,不是最初预期的用于内存检索,而是用于高效去重。
知识空白问题
Jina AI 的深度搜索是通过基于 FIFO(先进先出)队列的工作流实现的。起初,队列中只有用户的原始问题这一个项目。在对原始问题执行上述的搜索流程时,大语言模型会在「思」动作中向队列添加新的项目(即「知识空白」问题)。知识空白问题代表在回答主要问题之前,大模型需要填补的知识缺口。换句话说,前文介绍的 Jina AI 的深度搜索流程是运行在这个队列上的,它每次取队列中的第一个项目进行搜索。
这种工作流能够让大模型搜集更多的信息,例如当用户搜索「What is Jina AI?」时,大模型能够下钻到诸如 Jina AI 的创始人、团队构成、业务范围、研究成果等。特别地,大模型在执行后续项目的搜索时,会共享同一个上下文,也就是说在搜索 Jina AI 的研究成果时,大模型的上下文中会包含先前对团队构成和业务范围的搜索结果。
此外,这种工作流会在添加知识空白问题时,还会再将原问题添加到队列的末尾,如下面的代码所示。我认为,这种多次访问原问题的设计能够进一步提高搜索的深度和广度,因为共享上下文的设计会使得大模型在第二次访问原问题时已经知道了一些知识空白问题的答案,进而提出更多更好的知识空白问题。
// After identifying gap questions in reflect action
if (newGapQuestions.length > 0) {
// Add new questions to the front of the queue
gaps.push(...newGapQuestions);
// Always add original question to the end of the queue
gaps.push(originalQuestion);
}强制消费
Deepseek R1 的爆火在全世界范围内对用户的心智进行了深刻的影响,用户开始意识到如果给模型足够的时间思考就能获得更有用的结果,这种「延迟满足」的教育启发了 Jina AI。他们认为应当强制性地让大模型给出更多的知识空白问题,而不是只进行一两次搜索就草草了事。为此,Jina AI 向上述的深度搜索流程引入了「预算」的概念。
- 如果没有耗尽预算,则禁止大模型作出回答,而是要求添加知识空白问题。或者,也可安排另一个大模型对当前的搜索进展进行「挑刺」,指出一些合理的问题。
- 如果耗尽了预算,则要求大模型尽快给出答案。
深度研究(Deep Research)
Jina AI 的深度研究是基于深度搜索实现的,如下图所示。针对用户的问题,它会先生成一份研究报告的大纲,然后对大纲中的每个小节进行深度搜索,最终对各个小节的搜索结果进行汇总并输出最终的研究报告。
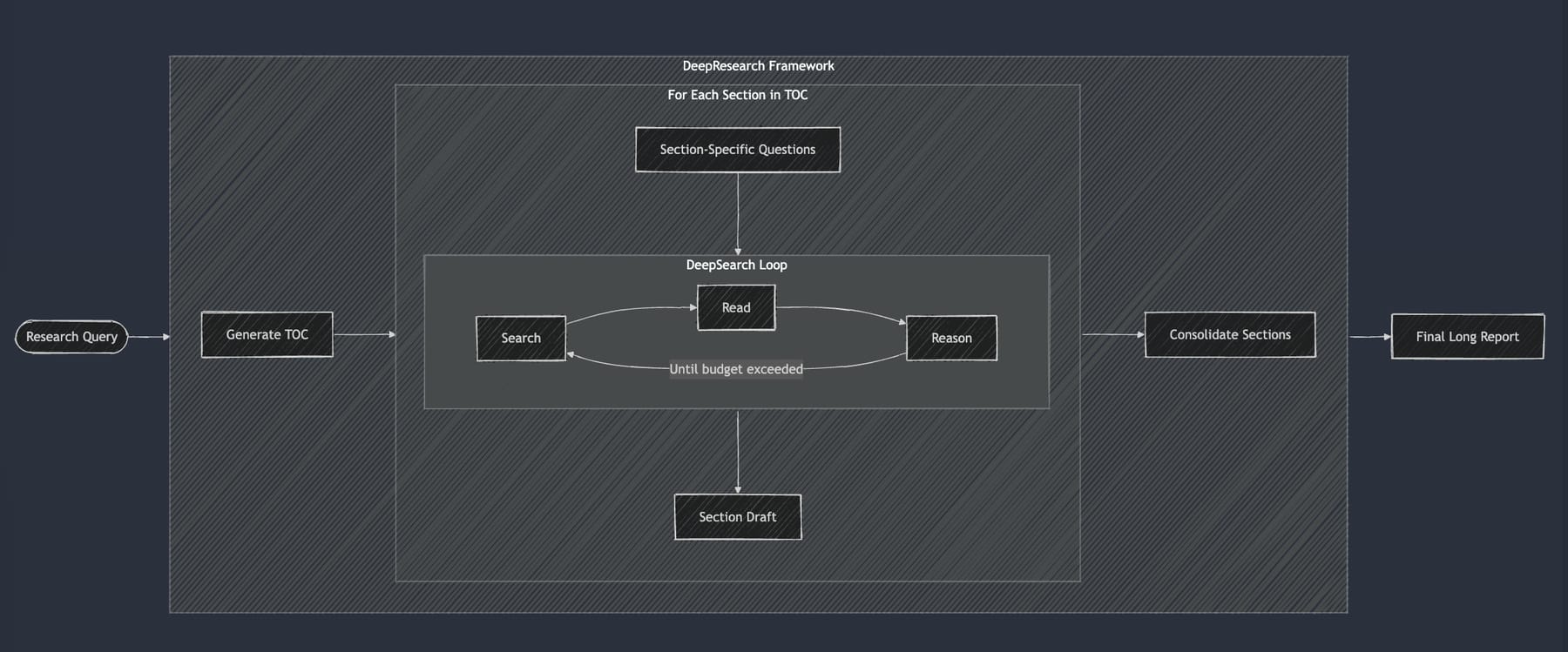
Jina AI 深度研究的流程图
关于 Agent 框架
Jina AI 的深度搜索并没有使用任何 Agent 框架。肖涵先生认为,目前主流的 Agent 框架的 sugar syntax 太多,跟模型底层离得太远,难以利用模型的新能力。这和我的观点一致,我认为市面上的一些 Agent 框架似乎陷入了一种怪圈:它们尝试在模式和共识尚未确定的当下,人为地固定一些模式并企图用它来解释新的问题。
我认为框架是人们对经验的共识性总结,但是在被称为 Agent 元年的今天,我们并没有很多共识度能上升到框架级别的经验。这些模型还给开发者带来了额外的复杂度,提高了学习成本。考虑到当前的大模型应用本身业务复杂度并不算高,框架带来的额外复杂度有时反而会让人觉得一头雾水。
目前,我认为最好用的 Agent 框架是 Vercel 的 AI SDK,它与其说是框架不如说是一个库,它只是谦卑地解决当前大模型应用的共识度最高的问题:抹平各个模型 API 的差异,提供最底层的公共数据结构定义和请求 API。
工作流和端到端
今年 2 月,OpenAI 发布了 Deep Research 功能,其输出的研究报告质量之高,让我感到相当震撼。他们的博客文章对这个功能的技术细节进行了如下所示的简单介绍,其中特别强调端到端训练能够提升模型处理现实问题的能力。
Deep research was trained using end-to-end reinforcement learning on hard browsing and reasoning tasks across a range of domains. Through that training, it learned to plan and execute a multi-step trajectory to find the data it needs, backtracking and reacting to real-time information where necessary. The model is also able to browse over user uploaded files, plot and iterate on graphs using the python tool, embed both generated graphs and images from websites in its responses, and cite specific sentences or passages from its sources. As a result of this training, it reaches new highs on a number of public evaluations focused on real-world problems.
OpenAI 在最近发表的 A practical guide to building agents 中将这种「依靠模型自发地完成任务的设计」称为 agent,它和这段时间 GitHub 上出现的深度研究的开源实现不同,后者大多是通过搭建各种奇妙的工作流实现的(这也包括 Jina AI 的深度研究),其中几个实现还宣称自己在一些评测集的表现略优于 OpenAI Deep Research,体现出了模型研究者和应用开发者之间的较量,前者通过训练模型来让模型学会执行复杂任务,后者则是通过人为地分解任务流程并结合 multi-agent system 等工程手段,通常不需要微调模型。
此外,OpenAI 在文章中下的定义在社区引起了一定争议,特别是它认为 agent 框架(agent framework)并不包括那些基于工作流的框架,与这些框架的作者们的宣传相悖。受到 Anthropic 在 Building effective agents 中对两者的定义的启发(它在社区中更受欢迎),在本文中我将会采用较为广泛的定义:将 OpenAI 所说的「依靠模型自发地完成任务」的做法称为「端到端(end-to-end)」,它和工作流都是 agent 的实现方式。这里的「端到端」实际上是相对的概念,我会在之后继续讨论这个话题。
在回答参会者的提问时,肖涵先生表示:端到端地微调出一个能够做好上述深度研究的完整流程的模型是非常困难的,特别是我们很难定义评估研究报告的量化标准,目前并没有看到成功训练的例子。我据此猜测:OpenAI 声称的「hard browsing and reasoning tasks across a range of domains」指的仅仅是深度搜索的部分,即模型能够端到端地围绕给定的主题(类似「知识空白问题」)自主地调用工具进行搜索,他们或许还使用了其它偏向工作流的方式生成完整的研究报告。
苦涩的教训
作为应用开发者,我一方面对这些开源实现的作者们感到钦佩,他们能够用相对落后的模型实现旗鼓相当的性能(OpenAI 宣称 Deep Research 使用的是极为强大的 o3 模型),另一方面也感到尴尬和迷茫。我认为深度搜索恰恰反映了在 2025 年的今天,大语言模型仍处于发展的早期阶段,模型研究者和应用开发者之间的职责界限尚未分明,他们经常会尝试解决一些相似的问题,从而让大模型变得更加有用。由于前者能从根本上决定模型的发展方向,因此后者提出的各种精妙的工程解法(特别是工作流)很容易过时,我将这种情况称为「角色冲突」。
早在去年,我已经在尝试使用 Claude 3.5 Sonnet 模型构建深度研究应用,它是基于 agent 实现的:我向大模型提供搜索网页和浏览网页的工具,并要求它自行决策如何完成任务。那时的我遇到了一个尴尬的问题:大语言模型总是倾向于认为它通过网络搜索获得的信息已经足以回答用户的问题,尽管它最后给出的答案几乎总是平庸的:缺乏细节、泛泛而谈,或者漏掉了某些信息点。于是,我转向基于工作流的实现:先要求大模型生成一份研究计划,再通过编程代码解析这份计划得到步骤列表,遍历列表的每一个项目并调用大模型进行搜索和总结,整体上较为类似 Jina AI 的深度搜索实现。
搭建这个工作流消耗了我相当多的时间。当支持 Reasoning 模式的 Claude 3.7 Sonnet 模型发布时,我惊讶地发现:直接将我的应用的原始版本(基于 agent 的实现)的模型切换到这一新模型,其表现能够平齐甚至超越基于工作流的新版本。这一经历让我意识到了应用开发者的局限性,也让我在之后看到类似 Jina AI 深度搜索这样基于工作流的实现方式时感到惋惜:模型开发者们不辞辛苦地通过工程量的累积提升的性能,模型研究者们似乎总能够以一种划时代的方式超越。当时的我认为,这简直就是 Richard Sutton 的那篇名为 The Bitter Lesson 的文章的翻版。
The Bitter Lesson 大致讲了这样的事情:在 AI 发展历史上,依靠规模化计算能力的通用方法最终总是战胜了基于人类专业知识和精心设计的特定方法。这篇文章指出,尽管研究者们不断尝试将人类领域知识注入 AI 系统,但随着时间推移,利用更多计算资源和更简单、更通用算法的方法总能取得更好的长期成果。这个「苦涩的教训」在于:专家级的领域知识工程虽然可以带来短期优势,但最终常被可扩展的计算方法所超越。
缓和冲突
肖涵先生在回答参会者的提问时提到,作为开发者的我们应该谨慎看待「苦涩的教训」,因为它最初是写给研究者的,面对当前模型在某些场景下能力尚未达到预期,我们不应因此停滞不前、被动等待,而应积极发挥自身作用,做力所能及的改进。我们需要在大模型快速发展的阶段,寻求开发者与研究者之间的平衡,缓解角色冲突。以我所在项目为例,我的选择是:充分发挥模型潜力,优先提升用户体验。
所谓「充分发挥模型潜力」,指的是倾向于以 agent 为中心构建应用。 这里并不是说所有的应用都应该放弃工作流而转向 agent,工作流和 agent 并非二元对立的关系,而是一个复杂系统在架构上展现出的倾向,正如 Langchain 在 How to think about agent frameworks 中提到「Nearly all of the "agentic systems" we see in production are a combination of "workflows" and "agents"」以及下面这段话:
Rather than having to choose whether or not something is an agent in a binary way, I thought, it would be more useful to think of systems as being agent-like to different degrees. Unlike the noun "agent", the adjective "agentic" allows us to contemplate such systems and include all of them in this growing movement.
Langchain 在这篇文章中表示,工作流的下限和上限都比端到端来得更高,而且能提供更强的确定性,而端到端则能带来更好的自主性(或者说面对大量边界情况时的灵活性),如下图所示:
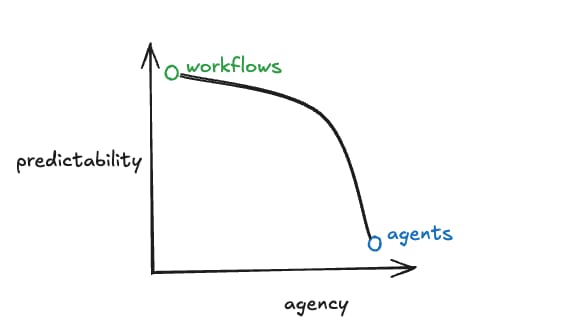
尽管工作流能够凭借人类知识的介入,以及大模型基础能力的不断提升,在复杂任务上获得相比端到端更好的上限(深度搜索就是这样的例子),但它需要我们投入大量的精力开发。如今,思考模型已成为研究热点,未来一段时间大模型的自主能力还会持续提升,逐步取代许多原本依赖工作流的场景。对于一些基于工作流的应用来说,由于它们的流程节点主要依赖大模型在特定子任务上的表现,整体效果往往受限于开发者在设计流程时所引入的人类知识,这也使得它们难以像基于智能体的应用那样充分利用模型自主能力提升所带来的红利。
选择「以 agent 为中心构建应用」本质上是一种权衡,我牺牲了一定的性能上限来换取开发其它更重要的事情的时间,而且随着大模型的不断发展,这些被牺牲的性能会被不断减少。之所以做这种牺牲,是因为我认为:目前多数的大模型应用的瓶颈并不在模型性能上,而是在用户体验上,它才是更重要的事情。这引出了下面的讨论。
所谓「优先提升用户体验」,就是大模型应用开发者应将主要精力投入到优化用户体验上。当前大模型研究的进步速度远超应用层面的创新,而开发者们却还在争论「聊天对话式 UI 是否适合现阶段的大模型应用」。从去年 8 月 Anthropic 推出的 Artifacts 到今年 OpenAI 的 Deep Research,我注意到,大家大多在努力还原和复刻这些功能本身,却很少真正从用户视角出发,思考并提升实际的使用体验。
以 OpenAI Deep Research 为例,我在使用的过程中遇到的最明显的问题是:我无法在研究中途看到进展。有时在等待十多分钟看到研究报告之后我才发现大模型理解错了我的意思,又或者是遗漏了一些调研对象。开发者们似乎也跟随着 OpenAI 默认了深度研究就应该是这种「一遍过」的模式,并且鼓励用户在发出请求后离开去做其它事情,等到研究完成再回来。
顺应模型的发展趋势,让我们更倾向于以智能体(agent)为核心来构建应用,这不仅节省了大量设计和维护工作流的精力,也让我们能够将更多关注点放在如何优化用户体验上。当应用性能相近时,真正能打动用户、留住用户的,往往是那些在细节和体验上做得更好的产品。我甚至认为,随着未来模型能力的持续提升,「工作流 vs 端到端」的争论会逐渐变得无关紧要,因为底层技术架构带来的性能差异会越来越小,届时应用之间的核心竞争力将更多体现在对不同用户群体的深度理解和差异化的体验设计上。