如何在 JavaScript 中优雅地创建并初始化数组
背景
孔乙己自己知道不能和他们谈天,便只好向孩子说话。有一回对我说道,“你会前端么?”我略略点一点头。他说,“写前端,……我便考你一考。创建数组,怎样写的?”我想,讨饭一样的人,也配考我么?便回过脸去,不再理会。孔乙己等了许久,很恳切的说道,“不会罢?……我教给你,记着!这些方法应该记着。将来被优化的时候,面试八股要用。”
别骂了,不过根据我自己看过的代码和经验,在 JavaScript 中创建一个定长的数组并初始化包括但不局限于以下方法:
[...Array(N).keys()].map((i) => i); // 1
Array(N).fill(null); // 2
Array(N)
.fill(null)
.map((i) => i); // 3
Array.from(Array(N), (_, i) => i); // 4
Array.from({ length: N }, (_, i) => i); // 5本文将结合 V8 引擎中有关数组的实现,对比上述几种创建数组的方法的优劣。虽然本文的内容主要针对 V8 引擎,但是其中涉及的优化设定可能也会出现在其它 JavaScript 引擎中。
JavaScript 数组内幕
学过 JavaScript 的人也许知道,数组表现得跟对象一样,它们都能够存储键值,而且数组实例的原型链还指向了对象示例的原型。因此不少人会将数组和对象混淆使用(尽管这不是一个好习惯)。不过数组和对象至少在语义上存在着显著的差别,我们「应该」用数组去存储和访问一段连续的内存空间,而引擎会对这种行为进行优化。
V8 官方博客上的文章 Elements kinds in V8 介绍了 V8 引擎是如何对数组实现进行特殊的设计以加速读写访问的。其中一个重要层面是对数组元素类型的界定,如下图所示:
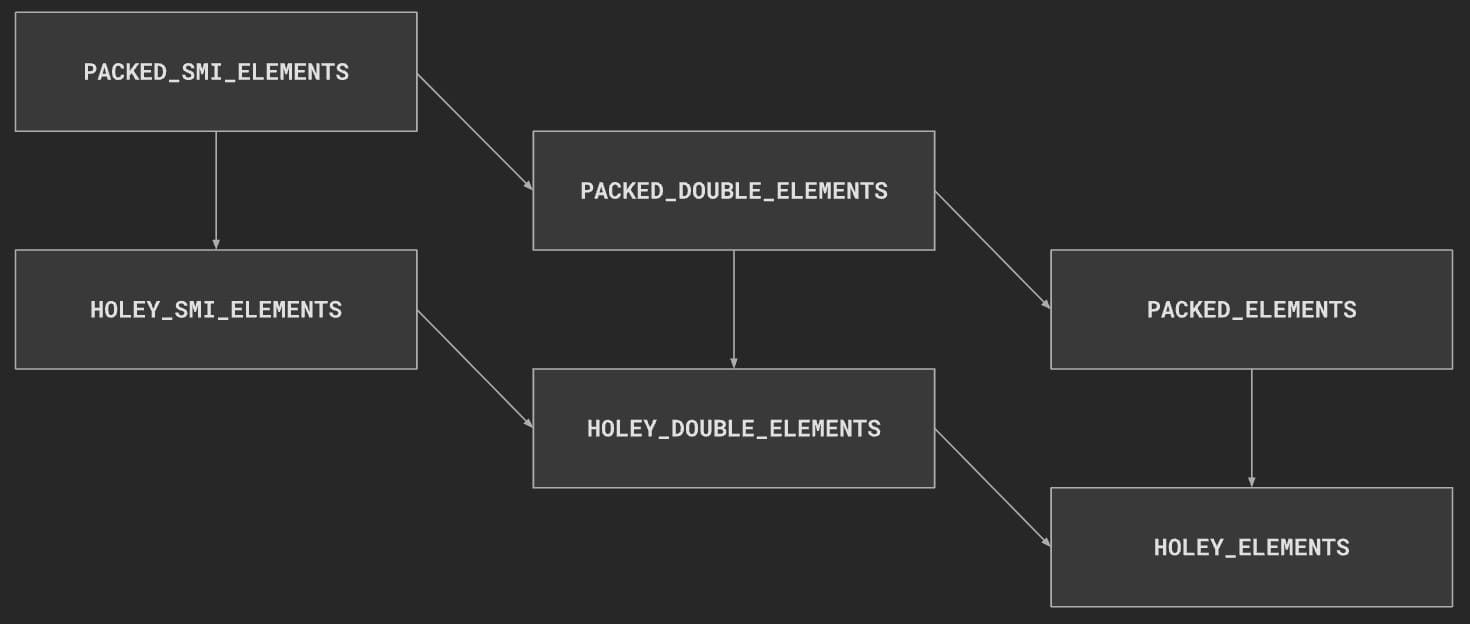
文章里说,V8 引擎会按照元素类型将数组分为若干不同的种类,上图展示了六个大致的种类:
PACKED_SMI_ELEMENTS:紧密的 SMI 元素。所谓的 SMI 大致上指的是 Small Integers(小整数)。PACKED_DOUBLE_ELEMENTS:紧密的双精度元素。应该指的是一般的 JavaScript 浮点数。PACKED_ELEMENTS:紧密元素,其中的类型囊括了上述两种,还可能包括其它类型。HOLEY_SMI_ELEMENTS:带洞的 SMI 元素。「带洞」的含义下文会介绍。HOLEY_DOUBLE_ELEMENTS:带洞的双精度元素。HOLEY_ELEMENTS:带洞元素。
为了方便,我们在下文中会使用「紧密数组」指代上述
PACKED开头的类型;使用「带洞数组」指代上述HOLEY开头的类型。
上图中的箭头表示了数组类型的转化方向。例如,如果一个 PACKED_SMI_ELEMENTS 的数组被写入了一个浮点数,那么它就会变成 PACKED_DOUBLE_ELEMENTS 类型。注意到这些转变目前是单向的,至少在 2017 年文章发表的时候 V8 引擎并没有办法进行逆向的转化。同时也注意到,true、null 和 undefined 这些值不被视为数字,因此将它们添加到紧密数组中也会将它转变为 PACKED_ELEMENTS 数组,带洞数组同理。
箭头同时也表示了 V8 引擎针对数组的优化的劣化方向,例如针对 SMI_ELEMENTS 类型数组的优化会比 DOUBLE_ELEMENTS 类型数组的优化更加细化,对前者的读写也可能会更快。此外,从底层的数据结构来看,SMI_ELEMENTS 类型和 DOUBLE_ELEMENTS 类型的数组读取性能会好于 ELEMENTS 类型的数组。也就是说一个仅包含数字的数组的读取性能会优于含有对象的数组(包括 null、undefined 等值)。感兴趣的读者可以观看 Google I/O 2012 - Breaking the JavaScript Speed Limit with V8,这个演讲还阐述了 V8 引擎的各种优化的实现原理以及针对开发者的建议。
查看数组类型
本文使用的验证数组类型的方法是通过向 v8 引擎中传入 --allow-natives-syntax 参数,并使用内置的调试函数 %DebugPrint() 来查看一个值的详情。其实 Node 也接受这个参数并传递给 v8 引擎。
$ node --allow-natives-syntax
Welcome to Node.js v20.0.0.
Type ".help" for more information.
> const array = []; %DebugPrint(array);
DebugPrint: 0x2430a652ef01: [JSArray]
- map: 0x0d47a5383969 <Map(PACKED_SMI_ELEMENTS)> [FastProperties]
- prototype: 0x3c433bb06019 <JSArray[0]>
- elements: 0x2af2e3141329 <FixedArray[0]> [PACKED_SMI_ELEMENTS]
- length: 0
- properties: 0x2af2e3141329 <FixedArray[0]>
- All own properties (excluding elements): {
0x2af2e31455f1: [String] in ReadOnlySpace: #length: 0x0c58184b6979 <AccessorInfo> (const accessor descriptor), location: descriptor
}
// ... 省略后面的输出
输出中 - elements 一行的 PACKED_SMI_ELEMENTS 即表示 array 的类型是紧密的 SMI 元素类型。
数组类型的转变
下面是一个例子,展示了我们如何通过向数组中添加不同类型的值导致数组类型发生改变:
const array = [1, 2, 3, 4, 5];
// PACKED_SMI_ELEMENTS
array.push(1.14);
// 包含一些小整数和一个浮点数
// PACKED_DOUBLE_ELEMENTS
array.push({});
// 又来了一个非数字
// PACKED_ELEMENTS带洞数组
所谓的带洞数组,指的是程序员通过一些手段破坏了 V8 引擎对紧密数组的假设:对于一个长度为 N 的紧密数组,它在从 0 到 N 上的每个索引都有值。下面的代码展示了如何将一个紧密数组变成带洞数组:
const array = [1, 1, 4, 5, 1, 4];
// 此时 array 还是紧密数组
array.length; // 6
array[9] = 0;
// 此时,数组在索引 6 到 8 上没有值,它变成了带洞数组此外,至少在 V8 引擎中,很多人使用的 new Array(N) 也会默认创建一个带洞数组。按照 ECMAScript 2022 Language Specification,以长度为参数调用数组的构造函数,其内部大致会发生下面的操作:
ArrayCreate(0),创建一个长度为0的数组对象Set(array, "length", intLen, true),将数组对象的length设为N- 返回数组对象
看到了吗?这里进行的操作跟上面的例子一样,破坏了 V8 引擎对于紧密数组的假设。
带洞数组相比于紧密数组存在下列的性能劣势,具体原因请见前文提到的 Presentation:
- 按照索引读值时,引擎需要执行额外的一些操作,拖慢速度。
- 带洞数组难以利用引擎内部实现的一些 Fast Path,下面我们会提到一个例子:
Array.reverse()。 - 带洞数组在理论上具备更多的限制,引擎无法对它的具体细节做进一步假设,因此难以应用未来的各种优化。
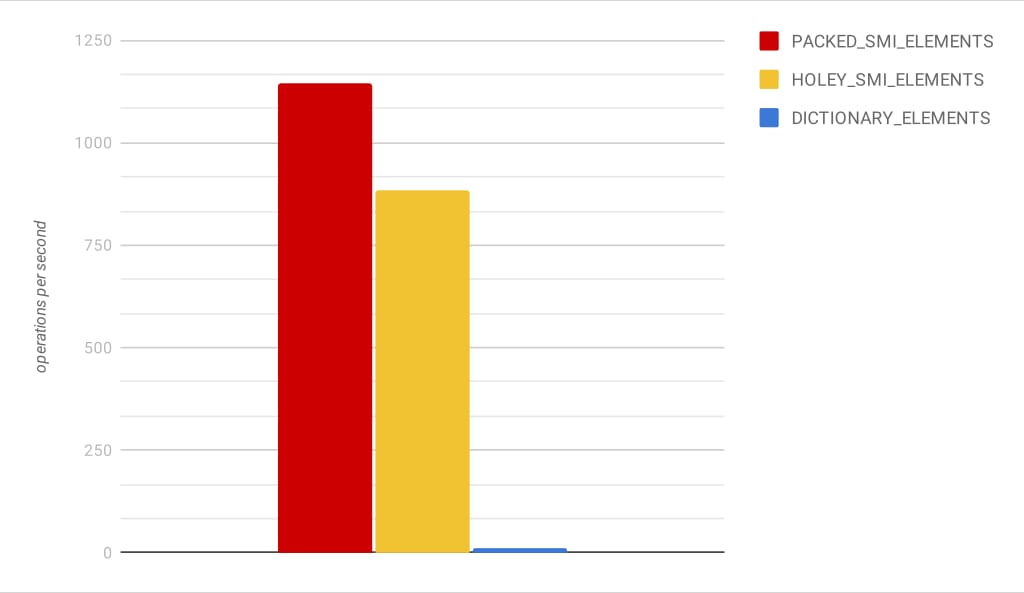
Andrey Pechkurov 在他的文章 Understanding Array Internals 中对比了带洞数组和紧密数组在一些场景下的性能表现,值得注意的是在下面的迭代读取性能测试中:
function sumArrayItems(arr) {
let sum = 0;
for (let i = 0; i < ITERATION_SIZE; i++) {
sum += arr[i];
}
return sum;
}作者得到了下图的结果,紧密数组的性能明显优于带洞数组:
另一个比较贴近生产的例子是 Array.reverse()。在 Chromium 的一个 issue Array.reverse() is 25x slower than an in-place swapping for loop? 中,楼主发现在 V8 引擎中调用带洞数组的 reverse() 函数要比直接用 for 循环实现要慢得多(大约 25 倍)。
问题的原因是 V8 引擎先前只对紧密数组的 reverse() 函数进行了优化,而没有对带洞数组进行优化。这个问题后来被修复了,带洞数组的 reverse() 函数会远快于使用 for 循环,但仍然比紧密数组慢一些。这在一定程度上反映了在 V8 引擎中带洞数组的各项优化可能不及紧密数组。
优雅的创建数组方法
在上面的 issue 中,楼主使用了这样的方法创建并初始化一个包含 1000000 个随机数的数组:
Array.from({ length: 1e6 }, (v, i) => Math.random() * 100);不要使用 for 循环
上面的方法看上去有些复杂,为什么不能用 for 循环呢:
const array = [];
for (let i = 0; i < 1e6; i++) {
array.push(Math.random() * 100);
}V8 引擎中对数组的实现和我们学习程序设计时使用的 malloc 类似,同样是分配一个连续的内存空间来存储数组元素。引擎很难知道我们要往里面填入 1000000 个元素,而且默认情况下分配的内存空间只能容纳数十个元素,当我们使用 push 函数添加更多元素时,V8 引擎会重新分配一个更大的内存空间,并将原来的元素复制到新的内存空间中。
因此,使用 for 循环会使 V8 引擎进行多次内存分配和复制,严重拖慢了速度。而使用 Array.from({ length: N }) 时,引擎可以根据给定的 N 事先分配好一个巨大的连续内存空间,不需要再进行多次的内存分配和复制。
V8 的优化
在上述的 issue 中,Choongwoo Han 还额外带来了一个优化:使 Array.of 和 Array.from 返回一个紧密数组。下面的几种创建数组的方法都能得到一个紧密数组:
Array.of(1, 2, 3);
Array.of(1, 2.5, 3);
Array.of.call(Array, Array(65536));
Array.from([1, 2, 3]);
Array.from({ length: 3 });
Array.from({ length: 3 }, (x) => 1);
Array.from({ length: 3 }, (x) => 1.5);笔者认为 Array.from 具有更高的实用价值,因为它接受第二个参数: (element, index) => value 用于初始化每一个值,比文章开头提到的 Array(N).fill(null).map() 这类方法要更为简单,同时它也给了引擎进行 Fast Path 优化的机会,就像 Choongwoo Han 在优化中做的一样:
try {
// Allocate an array with PACKED elements kind for fast-path rather than
// calling the constructor which creates an array with HOLEY kind.
if (c != GetArrayFunction()) goto CreateWithConstructor;
if (len > kMaxFastArrayLength) goto CreateWithConstructor;
const smiLen: Smi = 0;
const capacity: intptr = Convert<intptr>(len);
const map: Map = GetFastPackedSmiElementsJSArrayMap();
a = AllocateJSArray(
ElementsKind::PACKED_SMI_ELEMENTS, map, capacity, smiLen,
AllocationFlag::kAllowLargeObjectAllocation);
} label CreateWithConstructor {
typeswitch (c) {
case (c: Constructor): {
// a. Let A be ? Construct(C, « len »).
a = Construct(c, len);
}
case (JSAny): {
// a. Let A be ? ArrayCreate(len).
a = ArrayCreate(len);
}
}
}
在上面的代码中,Choongwoo Han 新增了一个创建紧密数组的 Fast Path,当我们对 Array.from 的调用满足下列条件时,会进入此 Fast Path 创建一个紧密数组对象:
this指向Array函数。- 第一个参数指定的 arrayLike 对象的长度(比如
Array.from({ length: N })中的N)小于kMaxFastArrayLength,目前它的值被设为32 * 1024 * 1024。
这个 Fast Path 发生在 ECMAScript 2022 Language Specification 的 Array.from 一节 的第 8 步和第 9 步之间。
结论
回顾文章开头的几种创建数组的方法:
[...Array(N).keys()].map((i) => i); // 1
Array(N).fill(null); // 2
Array(N)
.fill(null)
.map((i) => i); // 3
Array.from(Array(N), (_, i) => i); // 4
Array.from({ length: N }, (_, i) => i); // 5Choongwoo Han 的优化被合入了 V8 版本
11.0.141。目前仅覆盖了 Node 的20.0.0及以上版本。以及 Chromium M111 及以上版本。
笔者在 Node 版本 20.0.0(V8 版本 11.3.244.4-node.3)上通过 node --allow-natives-syntax 测试得到:
- 👎 不推荐。它确实创建了一个紧密数组,但它是先通过
Array(N)创建的数组,然后对Array(N).keys()进行复制产生的。这种创建和复制是不必要的,产生了额外的内存压力。 - 👎 不推荐。创建了一个带洞数组,类型为
HOLEY_ELEMENTS。 - 👎 不推荐。虽然创建了一个紧密数组,但类型为
PACKED_ELEMENTS。 - 👎 不推荐。虽然创建了一个类型为
PACKED_SMI_ELEMENTS的紧密数组,但没有必要使用Array(N)创建一个定长数组。规范中规定此时引擎要通过Array(N)的迭代器来迭代并设置对应索引的值,笔者认为和手动for-of并调用Array.push差不多,存在性能上的 overhead。 - 👍 推荐。创建了一个类型为
PACKED_SMI_ELEMENTS的紧密数组,同时 overhead 也是最少的。
以上的这些理由均基于「带洞数组的性能可能劣于紧密数组」的事实,尽管这项事实可能会随着 V8 引擎的不断优化变得越来越难以在生产环境中发生。如果你创建的数组都很小,或者不关心性能问题,那么你还是可以继续坚持自己最喜欢的方法。