如何打造可被摇树优化的库
本文由本人翻译,Usualminds 和 KimYangOfCat 校对,并发布在掘金上。

如何打造可被摇树优化的库
在 Theodo,我们致力于为我们的客户打造可靠、快速的应用。我们有一些改进现有应用的性能的项目。在其中一个项目里,我们通过对内部库进行摇树优化(tree shaking),成功将所有页面的 gzip 压缩后的 bundle 体积减少了足足 500KB。
在做这件事的时候,我们意识到摇树优化并不是一种简单地开启或关闭就会奏效的技术。有很多因素会影响一个库的摇树优化效果。
本文的目标是为构建适配摇树优化的库提供详细的指导。其中的步骤的总结如下:
- 在一个受控的环境下,针对一个已知的应用来检查我们的库是否可以被摇树优化。
- 使用 ES6 模块让打包工具(bundler)得以检测到未引用的
export语句。 - 使用副作用(side effects)优化,让你的库不包含任何副作用。
- 将库的代码逻辑分割到若干个小的模块中,同时保留库的模块树(module tree)。
- 在转译(transpile)库时,不要丢失模块树或者 ES 模块特征(ES modules characteristics)。
- 使用最新版的能够支持摇树优化的打包工具。
什么是摇树优化?为什么它很重要?
引用 MDN 文档:
Tree shaking 是一个通常用于描述移除 JavaScript 上下文中的未引用代码(dead code)行为的术语。
它依赖于 ES2015 中的
import和export语句,用来检测代码模块是否被导出、导入,且被 JavaScript 文件使用。
摇树优化是一种实现移除未引用代码(dead code elimination)的方式,实现的方式是检测哪些导出项(export)在应用代码里未被引用。它会被类似 Webpack 和 Rollup 这样的打包工具执行,最早由 Rollup 实现。
那么,为什么它叫摇树优化? 我们可以把应用的导出项(exports)和导入项(imports)想象成一棵树的样子。树上健康的叶子和树枝表示引用了的导入项。而死亡的叶子表示未引用的代码,它们和树的其他部分是分开的。这时候摇动这棵树,那么所有死亡的叶子会被摇下来,即未引用的代码会被移除。
为什么摇树优化很重要? 它能够对你的浏览器应用产生巨大的影响。如果应用打包了更多的代码,那么浏览器将花费更多时间去下载、解压、转换和执行它们。因此,对于打造速度最快的应用而言,移除未引用的代码至关重要。
网上有很多解释摇树优化和未引用代码移除的文章和资源。这里我们会集中讨论那些应用里中引用的库。当引用一个库的应用能够成功地移除这个库中未被引用的部分时,这个库才能被认为做到了摇树优化(tree shakeable)。
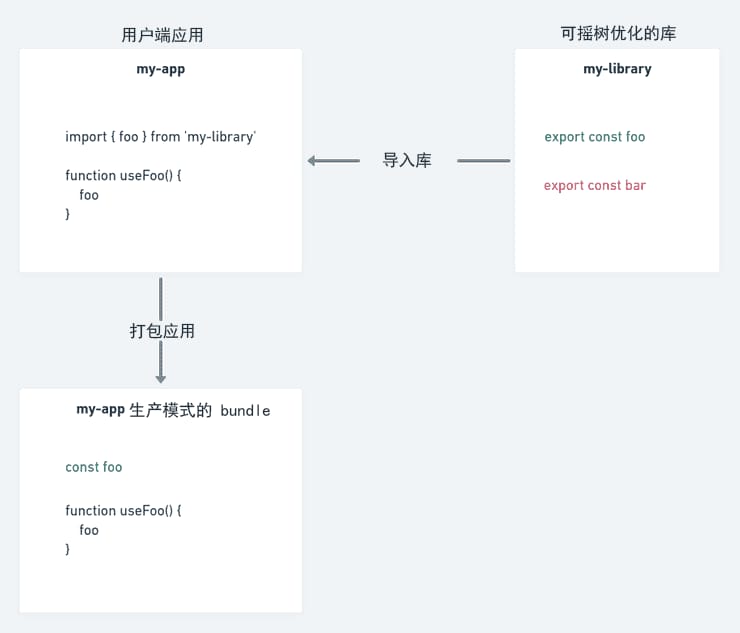
一个可摇树优化的库的例子
在尝试让一个库变得可被摇树优化之前,我们先来看看如何识别一个可摇树优化的库。
在受控环境下识别一个不可摇树优化的库
这乍看上去好像很简单,但是我注意到很多开发者都会认为他们的库是可摇树优化的,仅仅是因为它们使用了 ES6 模块(后文会细讲),或者是因为它们有对摇树优化很友好的配置。不幸的是,这并不意味着你的库实际上是可摇树优化的!
于是,我们被带到了这个问题上:如何高效地检查一个库是否可摇树优化?
要做到这件事,我们需要理解两件事情:
- 最终移除我们库中未引用代码的,是应用程序的打包工具,而不是库自己的打包工具(如果库有的话)。毕竟,只有应用程序自己知道使用了库的哪部分。
- 库的职责是确保它自己能够被最终的打包工具进行摇树优化。
要检查我们的库是否可摇树优化,我们可以将它放在一个受控的环境下,使用一个引用了它的应用进行测试:
- 创建一个简单的应用(我们称它为“引用应用”),给它搭配一个你会配置的打包工具,这个打包工具需要支持摇树优化(比如 Webpack 或者 Rollup)。
- 将被检查的库设置为应用的依赖。
- 仅仅导入库的一个元素,检查应用的打包工具的输出。
- 检查输出中是否只包含被导入的元素及其依赖。
这个策略能够将测试与我们现有的应用隔离。它可以让我们随意地摆弄库而不破坏任何东西。它还能让我们确保出现的问题不是来自于应用打包工具的配置上。
我们接下来会将这种策略应用到一个叫做 user-library 的库上,使用一个由 Webpack 进行打包的应用 user-app 进行测试。你也可以使用其他你更喜欢的打包工具。
user-library 的代码如下所示:
export const getUserName = () => "John Doe";
export const getUserPhoneNumber = () => "***********";它仅仅是在 index.js 文件里导出了两个函数,这两个函数可以通过 npm 包来使用。
让我们编写简单的 user-app:
package.json
{
"name": "user-app",
"version": "1.0.0",
"description": "",
"main": "index.js",
"scripts": {
"test": "echo \"Error: no test specified\" && exit 1",
"build": "webpack"
},
"author": "",
"license": "ISC",
"devDependencies": {
"webpack": "^5.18.0",
"webpack-cli": "^4.3.1"
},
"dependencies": {
"user-library": "1.0.0"
}
}注意,我们使用 user-library 作为依赖。
webpack.config.js
const path = require("path");
module.exports = {
entry: "./src/index.js",
output: {
filename: "main.js",
path: path.resolve(__dirname, "dist"),
},
mode: "development",
optimization: {
usedExports: true,
innerGraph: true,
sideEffects: true,
},
devtool: false,
};要理解上面的 Webpack 配置,我们需要先理解 Webpack 是如何进行摇树优化的。摇树优化进行的步骤如下所示:
- 识别出应用的入口文件(entry file)(由 Webpack 配置文件指定)
- 通过遍历入口文件导入的所有的依赖和它们各自的依赖,来创建应用的模块树(module tree)
- 对树中的每一个模块,识别出它的哪些
export语句没有被其他模块所导入。 - 使用像 UglifyJS 或者 Terser 这样的代码最小化(minification)工具来移除未引用的导出项,以及它们的相关代码。
这些步骤仅在 生产模式(production mode) 下才会被执行。
生产模式的问题在于代码最小化(minification)。它会让我们难以分辨摇树优化是否生效,因为在打包后的代码里我们看不到原来命名的函数。
为了绕过这个问题,我们会让 Webpack 运行在开发模式(development mode)下,但仍然让它识别哪些代码未被引用并且会在生产模式下被移除。我们将配置里的 optimization 设置成如下所示:
optimization: {
usedExports: true,
sideEffects: true,
innerGraph: true,
}其中的 usedExports 属性能够让 Webpack 识别哪些模块的导出项没有被其他模块引用。其他两个属性会在后文讨论。现在我们暂且认为它们能够提高我们的应用被摇树优化的效果。
我们 user-app 的入口文件:src/index.js
import { getUserName } from "user-library";
console.log(getUserName());打包之后,我们来分析一下输出:
/***/ "./node_modules/user-library/dist/index.js":
/*!*************************************************!*\
!*** ./node_modules/user-library/dist/index.js ***!
\*************************************************/
/***/ ((__unused_webpack_module, exports) => {
var __webpack_unused_export__;
__webpack_unused_export__ = ({ value: true });
const getUserName = () => 'John Doe';
const getUserPhoneNumber = () => '***********';
exports.getUserName = getUserName;
__webpack_unused_export__ = getUserPhoneNumber;
/***/ })Webpack 将我们所有的代码重新组织到了同一个文件里。请看其中的 getUserPhoneNumer 导出项,注意到 Webpack 将它标记为了未引用。它会在生产模式下被移除,而 getUserName 则会被保留,因为它被我们的入口文件 index.js 所使用。
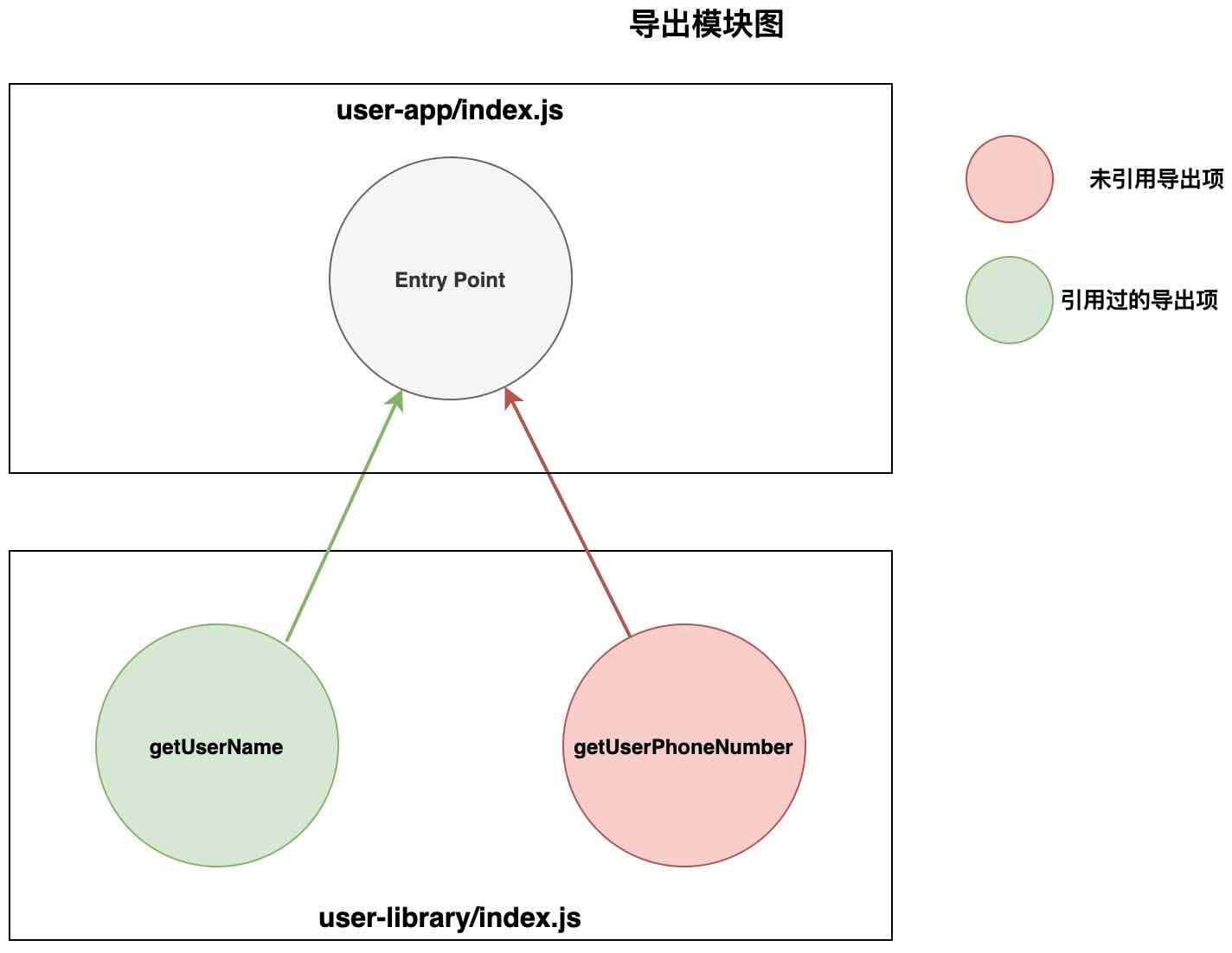
一个摇树优化后的库对应的一张简单的模块图
我们的库被摇树优化了!你可以再写一些导入项,重复上面的步骤再查看输出的代码。我们的目的是知道 Webpack 会把我们库里没有被引用的代码标记为未引用。
对于我们这个简单的 user-library 来说,一切看上去都还不错。让我们将它变得复杂一些,与此同时我们会关注摇树优化的一些条件和优化项。
使用 ES6 模块来让打包工具得以识别未被使用的 export
这项要求非常常见,而且很多文档都有详细的解释,但在我看来它们却有些误导性。我时常能听到一些开发者说,我们应该使用 ES6 模块来让我们的库能够被摇树优化。虽然这句话本身是完全正确的,但 其中包含一种错误的观念,这种观念以为仅仅使用 ES6 模块就足以让摇树优化很好地工作。 哎,要是真的这么简单,你也绝不会阅读本文至此!
不过,使用 ES6 模块确实是摇树优化的必要条件之一。
JavaScript 代码的打包格式有很多种:ESM、CJS、UMD、IIFE 等。
为简单起见,我们只考虑两种格式:ECMA Script 模块(ESM 或 ES6 模块)和 CommonJS 模块(CJS),因为它们在应用库中受到了最为广泛的使用。大多数库会使用 CJS 模块,因为这样能够让它们能够运行在 Node.js 应用里(不过 Node.js 现在也支持 ESM 了)。在 CJS 诞生很久之后的 2015 年,ES 模块才伴随 ECMAScript 2015(也被称作 ES6)出现,被认为是 JavaScript 的标准模块系统。
CJS 格式的例子:
const { userAccount } = require("./userAccount");
const getUserAccount = () => {
return userAccount;
};
module.exports = { getUserAccount };ESM 格式的例子:
import { userAccount } from "./userAccount";
export const getUserAccount = () => {
return userAccount;
};这两种格式有着很大的区别:ESM 的导入是静态的,而 CJS 的导入是动态的。 这意味着我们可以在 CJS 中做到以下的事情,但是在 ESM 中不行:
if (someCondition) {
const { userAccount } = require("./userAccount");
}虽然这样看上去更加灵活,但它也意味着打包工具不能在编译或打包期间构造出一棵有效的模块树。someCondition 这个变量只有在运行时才能知道它的值,导致打包工具在编译期间无论 someCondition 的值是什么都会把 userAccount 给导入进来。这也导致打包工具无法检查这些导入项是否真的被使用了,于是把所有 CJS 格式的导入项打包进 bundle 里。
让我们修改 user-library 的代码来体现这一点。同时,为了让这个库显得更贴近现实,它现在有两个文件:
src/userAccount.js
const userAccount = {
name: "user account",
};
module.exports = { userAccount };src/index.js
const { userAccount } = require("./userAccount");
const getUserName = () => "John Doe";
const getUserPhoneNumber = () => "***********";
const getUserAccount = () => userAccount;
module.exports = {
getUserName,
getUserPhoneNumber,
getUserAccount,
};我们保持 user-app 的入口文件不变,这样我们依然不会用到 getUserAccount 函数及其依赖。
/*!*************************************************!*\
!*** ./node_modules/user-library/dist/index.js ***!
\*************************************************/
/***/ ((module, __unused_webpack_exports, __vite_rsc_require__) => {
const { userAccount } = __vite_rsc_require__(/*! ./userAccount */ "./node_modules/user-library/dist/userAccount.js")
const getUserName = () => 'John Doe'
const getUserPhoneNumber = () => '***********'
const getUserAccount = () => userAccount
module.exports = {
getUserName,
getUserPhoneNumber,
getUserAccount
}
/***/ }),
/***/ "./node_modules/user-library/dist/userAccount.js":
/*!*******************************************************!*\
!*** ./node_modules/user-library/dist/userAccount.js ***!
\*******************************************************/
/***/ ((module) => {
const userAccount = {
name: 'user account'
}
module.exports = { userAccount }
/***/ })这三个导出项全部都出现在打包输出里,并且没有被 Webpack 标记为未引用。对于源文件 userAccount 也是如此。
现在,让我们来看看将上面的例子改造成 ESM 之后的结果。我们做的修改是将 require 和 exports 的语法全部改成对应的 ESM 的语法。
/*!*************************************************!*\
!*** ./node_modules/user-library/dist/index.js ***!
\*************************************************/
/***/ ((__unused_webpack_module, __webpack_exports__, __vite_rsc_require__) => {
/* harmony export */ __vite_rsc_require__.d(__webpack_exports__, {
/* harmony export */ "getUserName": () => /* binding */ getUserName
/* harmony export */ });
/* unused harmony exports getUserAccount, getUserPhoneNumber */
/* harmony import */ var _userAccount_js__WEBPACK_IMPORTED_MODULE_0__ = __vite_rsc_require__(/*! ./userAccount.js */ "./node_modules/user-library/dist/userAccount.js");
const getUserName = () => 'John Doe';
const getUserPhoneNumber = () => '***********';
const getUserAccount = () => userAccount;
/***/ }),
/***/ "./node_modules/user-library/dist/userAccount.js":
/*!*******************************************************!*\
!*** ./node_modules/user-library/dist/userAccount.js ***!
\*******************************************************/
/***/ ((__unused_webpack_module, __webpack_exports__, __vite_rsc_require__) => {
/* unused harmony export userAccount */
const userAccount = {
name: 'user account'
};
/***/ })注意,getUserAccount 和 getUserPhoneNumber 都被标记为了未引用。而且另一个文件里的 userAccount 也被标记了。得益于 innerGraph 优化,Webpack 能够将 index.js 文件里的 getUserAccount 导入项链接到 userAccount 导出项。这让 Webpack 可以从入口文件开始,递归遍历它所有的依赖,进而知道每一个模块的哪些导出项未被引用。 因为 Webpack 知道 getUserAccount 没有被使用,所以它可以到 userAccount 文件里对 getUserAccount 的依赖做相同的检查。
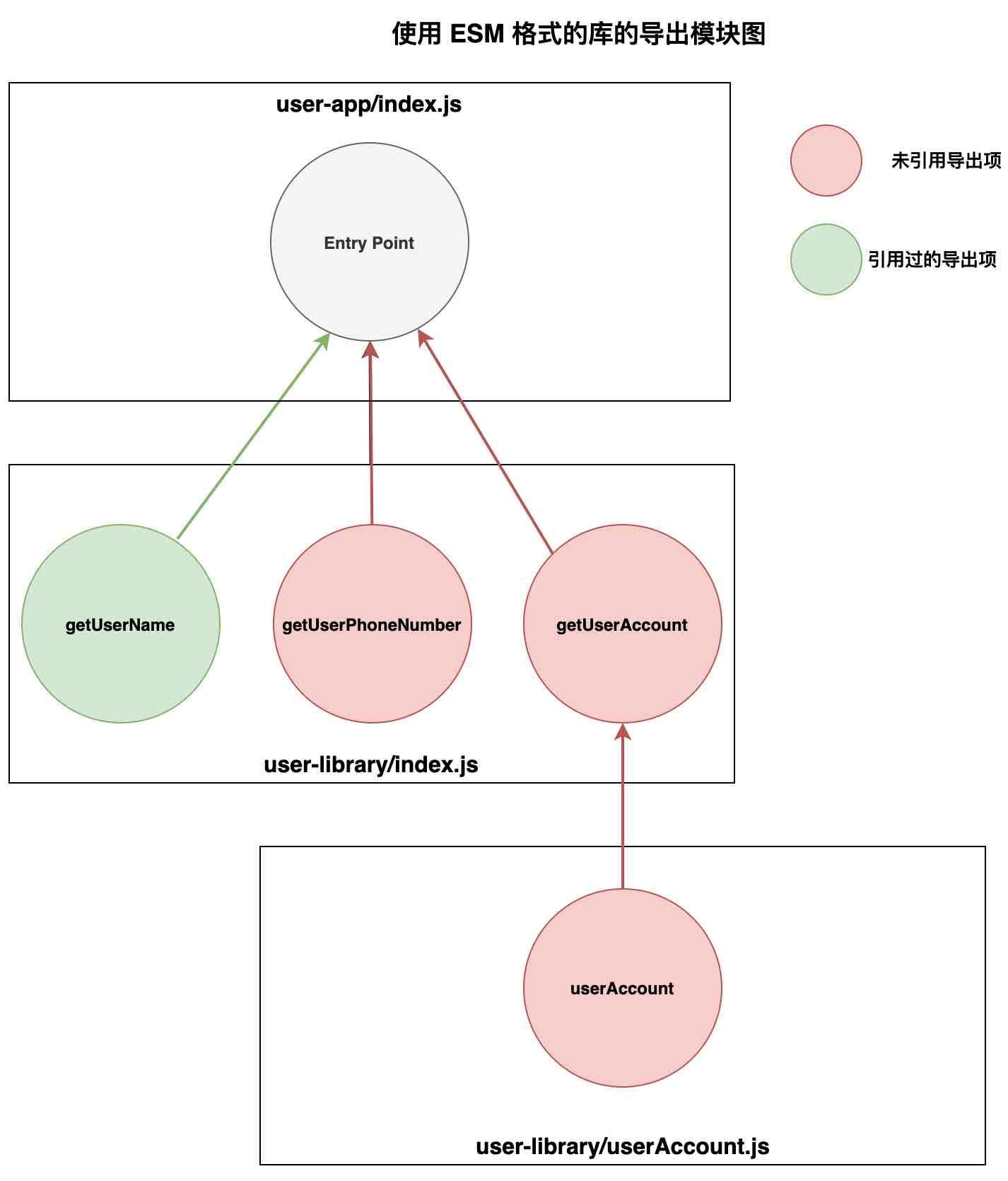
使用 ESM 格式的库的导出模块图
ES 模块让我们可以在应用代码里寻找那些被引用的和未被引用的导出项,这也解释了为什么这种模块系统对于摇树优化是如此的重要。它还解释了为什么我们应该使用像 lodash-es 这样导出了兼容 ESM 的构建产物的依赖。这里 lodash-es 库是很受欢迎的 lodash 库的 ESM 版本。
话虽如此,针对摇树优化,仅仅使用 ES 模块仍然不是最佳的方法。在我们的例子里,我们发现 Webpack 会在每个文件递归地检查导出的代码是否被引用。对于我们的例子来说,Webpack 其实可以直接忽略掉 userAccount 文件,因为它唯一的导出项是未引用的!这就将我们引入到文章接下来对副作用(side effect)的讨论。
本文这一部分的总结如下:
- ESM 是摇树优化的条件之一,但仅凭它不足以让摇树优化达到理想效果。
- 确保你的库总是提供一份 ESM 格式的编译产物! 如果你的库的用户需要 ESM 和 CJS 格式的编译产物,可以通过 package.json 中的
main和module属性来设置。 - 如果可以的话,确保总是使用 ESM 格式的依赖,否则它们不能被摇树优化。
使用副作用优化来让你的库不包含副作用
根据 Webpack 的文档,摇树优化可以被分为以下两种优化措施:
- 引用导出(usedExports):判定一个模块的哪些导出项是被引用的或未被引用。
- 副作用(sideEffects):略过那些不包含任何被引用的导出项并且不包含副作用的模块。
为了阐释副作用的含义,让我们看看之前用到的例子:
import { userAccount } from "./userAccount";
function getUserAccount() {
return userAccount;
}如果 getUserAccount 没有被使用,打包工具是否可以认为 userAccount 模块可以从打包输出中移除呢?答案是否定的!userAccount 可以做各种能够影响应用的其他部分的事情。它可以向全局可访问的值里注入一些变量,比如 DOM。它还可以是一个 CSS 模块,会向 document 里注入样式。不过我觉得最好的例子是 polyfill。我们通常会像下面这样引入它们:
import "myPolyfill";现在这个模块一定有副作用了,因为一旦它被导入到其他模块,它就会影响到整个应用的代码。打包工具会将这个模块视为可能被删除的候选者,毕竟我们没有使用它的任何导出项。不过移除它会破坏我们应用的正常运行。
像 Webpack 和 Rollup 这样的打包工具也因此会默认地将我们库中的所有模块视为包含副作用。
但是在前面的例子里,我们知道我们的库不包含任何副作用!因此,我们可以告诉打包工具这一点。大多数打包工具可以读取 package.json 文件里的 sideEffects 属性。这个属性如果没有指定,那么它默认会被设为 true(表示这个包里所有的模块都含有副作用)。我们可以将它设为 false(表示所有模块都不包含副作用)或者也可以指定一个数组,列举出含有副作用的源文件。
我们将这个属性添加到 user-library 库的 package.json 中:
{
"name": "user-library",
"version": "1.0.0",
"description": "",
"sideEffects": false,
"main": "dist/index.js",
"scripts": {
"test": "echo \"Error: no test specified\" && exit 1"
},
"author": "",
"license": "ISC"
}然后重新运行 Webpack 进行打包:
/*!*************************************************!*\
!*** ./node_modules/user-library/dist/index.js ***!
\*************************************************/
/***/ (__unused_webpack_module, __webpack_exports__, __vite_rsc_require__) => {
/* harmony export */ __vite_rsc_require__.d(__webpack_exports__, {
/* harmony export */ getUserName: () => /* binding */ getUserName,
/* harmony export */
});
/* unused harmony exports getUserAccount, getUserPhoneNumber */
const getUserName = () => "John Doe";
const getUserPhoneNumber = () => "***********";
const getUserAccount = () => userAccount;
/***/
};我们发现,源文件 userAccount 已经在打包输出中被移除了。我们仍然能够看到 getUserAccount 函数在引用 userAccount,不过此函数已经被 Webpack 标记为了未引用代码,它会在代码最小化的过程中被移除。
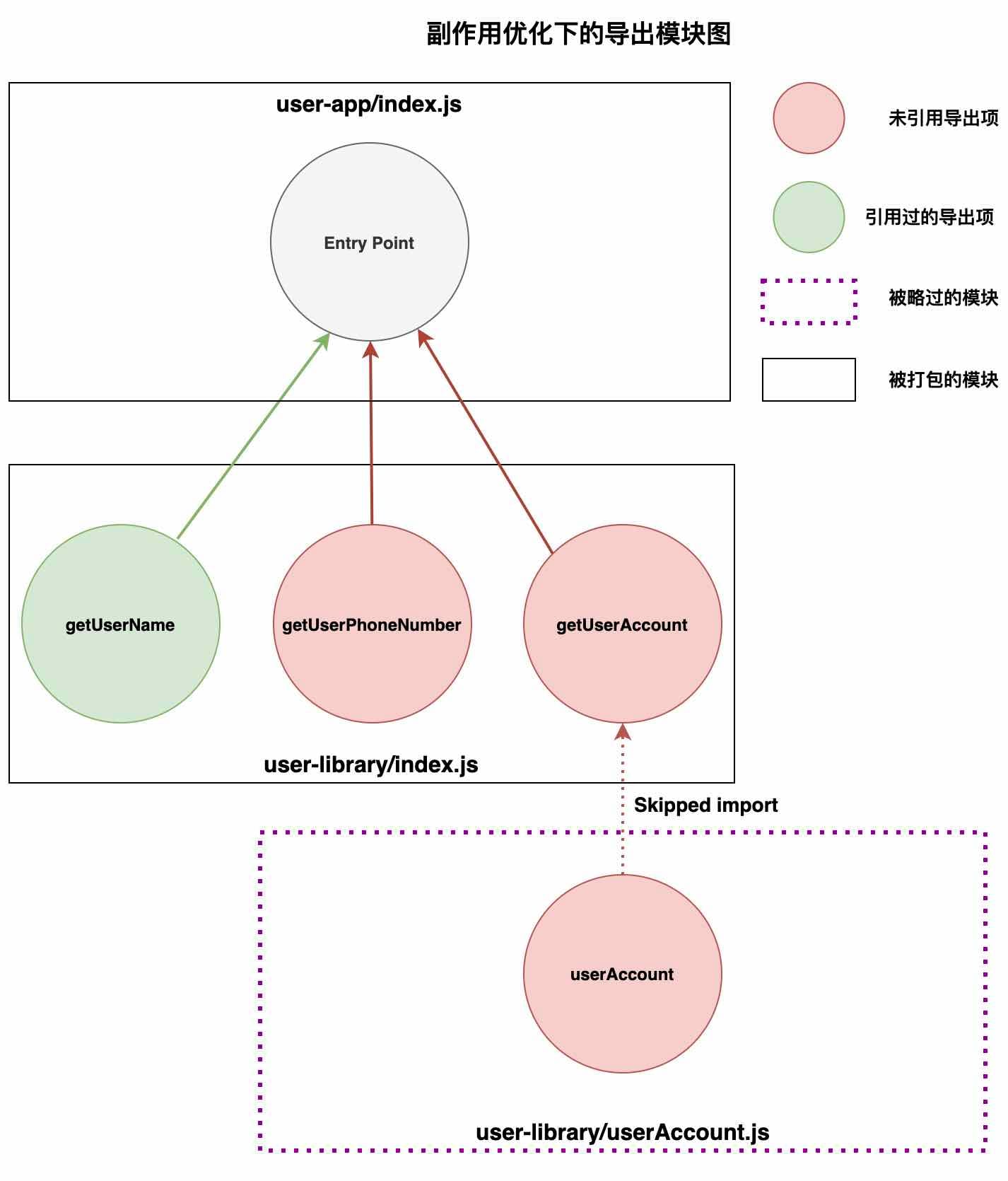
副作用优化下的模块图
sideEffects 选项对于那些通过一个 index 文件从其他内部源文件导出 API 的库尤其重要。 如果没有副作用优化,打包工具就必须解析所有包含导出项的源文件。
正如 Webpack 的提示:“sideEffects 非常地高效,因为它能够让打包工具略过整个的模块或源文件,以及它的整个子树”
对于前文介绍的两种优化措施在介入打包过程上的不同之处,简单来说如下所述:
sideEffects让打包工具略过一个被导入的模块,如果从这个模块导入的东西全部都没有被使用的话。usedExports让打包工具移除在一个模块里未被引用的导出项。
那么,上面两种措施,一个是“略过文件”,一个是“将导出项标记为未被使用”。前者影响下的打包输出又和后者有什么不同之处呢?
大多数情况下,对一个库进行摇树优化,有和没有副作用优化其实会产生一模一样的输出。最终的 bundle 里包含的代码量是一样的。不过在某些情况下,如果分析未引用的导出项的相关代码的过程过于复杂,那么有和没有副作用优化的结果就不一样了。本文接下来的部分将包含这两种情况的例子,我们将看到只有小的模块和开启副作用优化的组合产生了最好的打包产物。
这一部分的总结如下:
- 摇树优化包含两个部分:引用导出(used exports)优化和副作用(side effects)优化。
- side effects 优化相比起检测每个模块中未被使用的导出项,有更高的效率。
- 不要在你的库里引入任何副作用。
- 一定要通过
package.json文件里的sideEffects属性告诉打包工具:你的库不包含任何副作用。
通过保留库的模块树并将代码分割到小的模块中,来让你的库从 side effects 优化中充分获益
你可能注意到我们在本文先前的例子里的 user-library 并没有被打包到一个单独的文件里,而是直接暴露手动加入的 .js 源文件。
通常,一个库会由于以下原因被打包:
- 使用了一些自定义的
import路径。 - 使用的是像 Sass 或者 TypeScript 这样的语言,它们需要转换到比如 CSS 或者 JavaScript 这样的语言。
- 需要满足于提供多种模块格式(ESM、CJS、IIFE 等)的需求。
像 Webpack、Rollup、Parcel 和 ESBuild 这样的流行的打包工具被设计为用来提供一个能够传输给浏览器使用的 bundle。它们也因此倾向于创建一个单独的的文件,然后将你的所有代码重新组合并输出到这个文件里,从而只有一个单独的 .js 文件需要通过网络进行传输。
从摇树优化的角度来说,这导致了一个问题:副作用优化不复存在了,因为没有模块能够被略过。
我们将列举两种情况来说明:对摇树优化来说,分割模块搭配副作用优化是必须的。
一个库模块导入一个 CJS 格式的依赖
为了演示这个问题,我们将使用 Rollup 来打包我们的库。同时,我们将让库的其中一个模块导入一个 CJS 格式的依赖:Lodash。
rollup.config.js
export default {
input: "src/index.js",
output: {
file: "dist/index.js",
format: "esm",
},
};userAccount.js
import { isNil } from "lodash";
export const checkExistance = (variable) => !isNil(variable);
export const userAccount = {
name: "user account",
};注意,我们现在将导出 checkExistance,然后将它导入到我们库的 index.js 文件里。
以下是打包输出的文件 dist/index.js:
import { isNil } from "lodash";
const checkExistance = (variable) => !isNil(variable);
const userAccount = {
name: "user account",
};
const getUserAccount = () => {
return userAccount;
};
const getUserPhoneNumber = () => "***********";
const getUserName = () => "John Doe";
export { checkExistance, getUserName, getUserPhoneNumber, getUserAccount };所有文件都被打包到了一个单独的文件里。注意 Lodash 也在此文件的顶部被导入。我们在 user-app 里仍然导入和以前一样的函数,这意味着 checkExistance 函数依然未被引用。然而,在运行 Webpack 打包 user-app 之后,我们发现即使 checkExistance 函数被标记为了未引用,整个 Lodash 库仍然被导入了:
/***/ "./node_modules/user-library/dist/index.js":
/*!*************************************************!*\
!*** ./node_modules/user-library/dist/index.js ***!
\*************************************************/
/***/ ((__unused_webpack_module, __webpack_exports__, __vite_rsc_require__) => {
"use strict";
/* harmony export */ __vite_rsc_require__.d(__webpack_exports__, {
/* harmony export */ "getUserName": () => (/* binding */ getUserName)
/* harmony export */ });
/* unused harmony exports checkExistance, userAccount, getUserPhoneNumber, getUserAccount */
/* harmony import */ var lodash__WEBPACK_IMPORTED_MODULE_0__ = __vite_rsc_require__(/*! lodash */ "./node_modules/user-library/node_modules/lodash/lodash.js");
/* harmony import */ var lodash__WEBPACK_IMPORTED_MODULE_0___default = /*#__PURE__*/__vite_rsc_require__.n(lodash__WEBPACK_IMPORTED_MODULE_0__);
const checkExistance = (variable) => !isNil(variable);
const userAccount = {
name: "user account",
};
const getUserPhoneNumber = {
number: '***********'
};
const getUserAccount = () => {
return userAccount
};
const getUserName = () => 'John Doe';
/***/ }),
/***/ "./node_modules/user-library/node_modules/lodash/lodash.js":
/*!*****************************************************************!*\
!*** ./node_modules/user-library/node_modules/lodash/lodash.js ***!
\*****************************************************************/
/***/ (function(module, exports, __vite_rsc_require__) {
/* module decorator */ module = __vite_rsc_require__.nmd(module);
var __WEBPACK_AMD_DEFINE_RESULT__;/**
* @license
* Lodash <https://lodash.com/>
* Copyright OpenJS Foundation and other contributors <https://openjsf.org/>
* Released under MIT license <https://lodash.com/license>
* Based on Underscore.js 1.8.3 <http://underscorejs.org/LICENSE>
* Copyright Jeremy Ashkenas, DocumentCloud and Investigative Reporters & Editors
*/
// ...Webpack 无法对 Lodash 进行摇树优化,因为它的模块格式是 CJS。这挺让人失望的,毕竟我们都很明显地组织好了我们的库,让 Lodash 仅在 userAccount 模块里被导入,而且这个模块也没有被我们的应用所引用。如果模块结构能够保留,Webpack 就能受益于副作用优化,从而能够检测到 userAccount 的导出项都未被引用然后直接略过这个模块,这样的话 Lodash 就不会被打包了。
在 Rollup 中,我们可以使用 preserveModules 选项来保留库的模块结构。其他打包工具也有类似的选项。
export default {
input: "src/index.js",
output: {
dir: "dist",
format: "esm",
preserveModules: true,
},
};Rollup 现在能够保留原本的文件结构了,我们再次运行 Webpack,得到以下的打包输出:
/***/ "./node_modules/user-library/dist/index.js":
/*!*************************************************!*\
!*** ./node_modules/user-library/dist/index.js ***!
\*************************************************/
/***/ ((__unused_webpack_module, __webpack_exports__, __vite_rsc_require__) => {
/* harmony export */ __vite_rsc_require__.d(__webpack_exports__, {
/* harmony export */ "getUserName": () => (/* binding */ getUserName)
/* harmony export */ });
/* unused harmony export getUserAccount */
const getUserAccount = () => {
return userAccount
};
const getUserName = () => 'John Doe';
/***/ })Lodash 现在和 userAccount 模块一起被略过了。
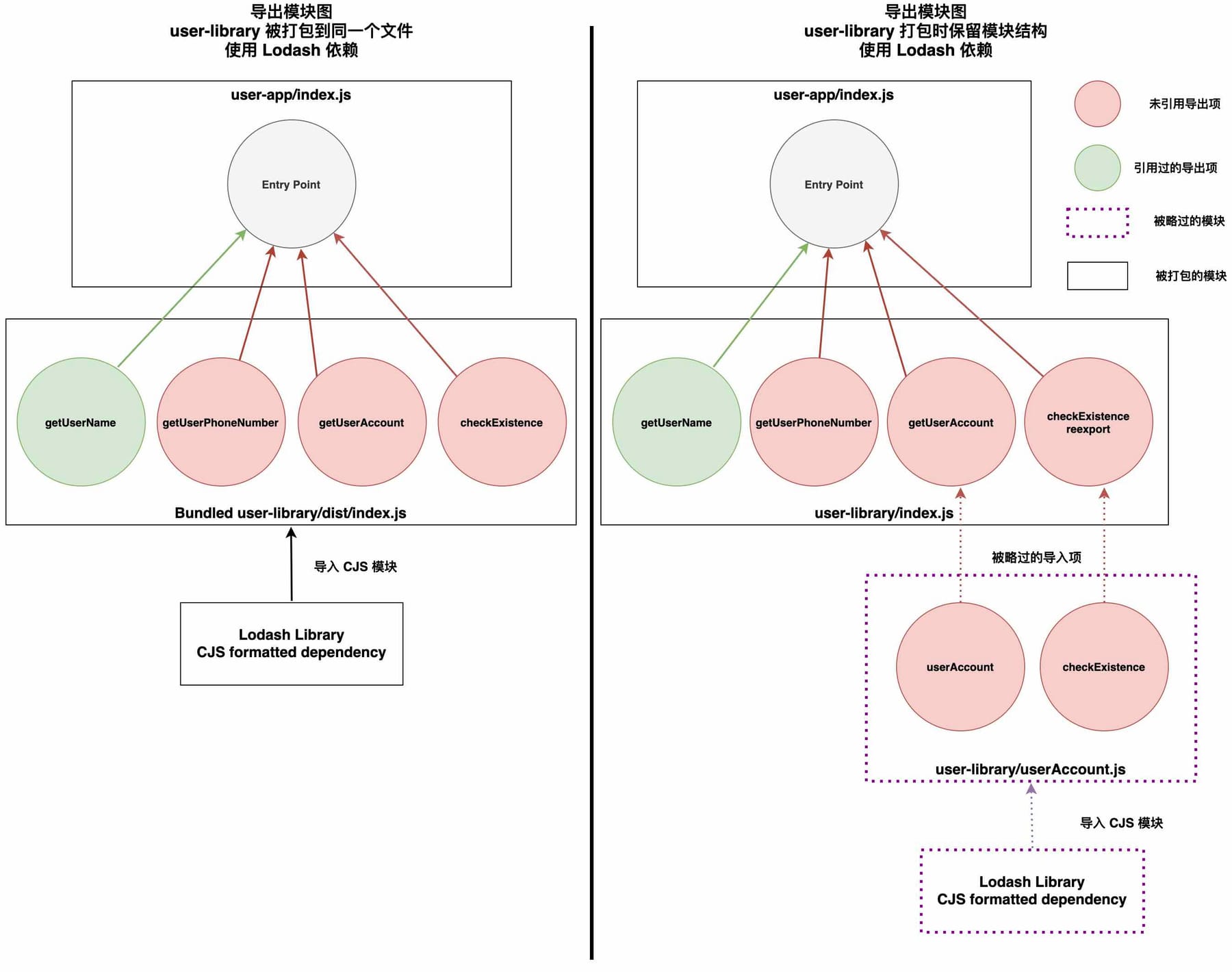
在使用 CJS 格式的依赖时,保留模块结构能够改善摇树优化效果
代码分割
保留分割后的模块结构以及开启副作用优化也有助于 Webpack 的代码分割。它对于大型应用来说是一个关键的优化措施,被广泛应用于那些含有多个页面的 Web 应用。像 Nuxt 和 Next 这样的框架都会给各个页面配置代码分割。
为了演示代码分割带来的好处,我们先来看看如果我们的库被打包到了一个单独的文件时会发生什么。
user-library/src/userAccount.js
export const userAccount = {
name: "user account",
};user-library/src/userPhoneNumber.js
export const userPhoneNumber = {
number: "***********",
};user-library/src/index.js
import { userAccount } from "./userAccount";
import { userPhoneNumber } from "./userPhoneNumber";
const getUserName = () => "John Doe";
export { userAccount, getUserName, userPhoneNumber };为了对我们的应用进行代码分割,我们会使用 Webpack 的 import 语法。
user-app/src/userService1.js
import { userAccount } from "user-library";
export const logUserAccount = () => {
console.log(userAccount);
};user-app/src/userService2.js
import { userPhoneNumber } from "user-library";
export const logUserPhoneNumber = () => {
console.log(userPhoneNumber);
};user-app/src/index.js
const main = async () => {
const { logUserPhoneNumber } = await import("./userService2");
const { logUserAccount } = await import("./userService1");
logUserAccount();
logUserPhoneNumber();
};
main();打包产生的文件现在有三个:main.js、src_userService1_js.main.js 和 src_userService2_js.main.js。仔细查看 src_userService1_js.main.js 的内容,我们可以发现整个 user-library 都被打包了:
(self["webpackChunkuser_app"] = self["webpackChunkuser_app"] || []).push([
["src_userService1_js"],
{
/***/ "./node_modules/user-library/dist/index.js":
/*!*************************************************!*\
!*** ./node_modules/user-library/dist/index.js ***!
\*************************************************/
/***/ (
__unused_webpack_module,
__webpack_exports__,
__vite_rsc_require__
) => {
"use strict";
/* harmony export */ __vite_rsc_require__.d(__webpack_exports__, {
/* harmony export */ userAccount: () => /* binding */ userAccount,
/* harmony export */ userPhoneNumber: () =>
/* binding */ userPhoneNumber,
/* harmony export */
});
/* unused harmony export getUserName */
const userAccount = {
name: "user account",
};
const userPhoneNumber = {
number: "***********",
};
const getUserName = () => "John Doe";
/***/
},
/***/ "./src/userService1.js":
/*!*****************************!*\
!*** ./src/userService1.js ***!
\*****************************/
/***/ (
__unused_webpack_module,
__webpack_exports__,
__vite_rsc_require__
) => {
"use strict";
__vite_rsc_require__.r(__webpack_exports__);
/* harmony export */ __vite_rsc_require__.d(__webpack_exports__, {
/* harmony export */ logUserAccount: () =>
/* binding */ logUserAccount,
/* harmony export */
});
/* harmony import */ var user_library__WEBPACK_IMPORTED_MODULE_0__ = __vite_rsc_require__(
/*! user-library */ "./node_modules/user-library/dist/index.js"
);
const logUserAccount = () => {
console.log(user_library__WEBPACK_IMPORTED_MODULE_0__.userAccount);
};
/***/
},
},
]);虽然 getUserName 被标记为了未引用,但 userAccount 并没有被标记,即使 userService2 仅仅使用了 userPhoneNumber。为什么会这样呢?(译注:原文中上面的代码是 userService1 的而不是 userService2)
我们需要记住,引用导出(used exports)优化在检查导出项是否被引用的时候,是在模块层面上检查的。只有从这个层面上 Webpack 才能移除那些未被使用的代码。对于我们的库模块来说,userAccount 和 userPhoneNumber 其实都被使用了。在这个情况下,Webpack 并不能区分清 userService1 和 userService2 在导入项上的区别,正如下图所示(你会发现 userAccount 和 userPhoneNumber 都被标注为绿色):

代码分割导致摇树优化出现的问题
这意味着 Webpack 在仅依靠引用导出优化的条件下,并不能独立地针对每个 chunk 进行摇树优化。
现在,让我们在打包库时保留模块结构,这样副作用优化就能工作:
Webpack 仍然输出了 3 个文件,不过这一次 src_userService2_js.main.js 仅仅包含了 userPhoneNumber 里的代码:
(self["webpackChunkuser_app"] = self["webpackChunkuser_app"] || []).push([
["src_userService2_js"],
{
/***/ "./node_modules/user-library/dist/userPhoneNumber.js":
/*!***********************************************************!*\
!*** ./node_modules/user-library/dist/userPhoneNumber.js ***!
\***********************************************************/
/***/ (
__unused_webpack_module,
__webpack_exports__,
__vite_rsc_require__
) => {
"use strict";
/* harmony export */ __vite_rsc_require__.d(__webpack_exports__, {
/* harmony export */ userPhoneNumber: () =>
/* binding */ userPhoneNumber,
/* harmony export */
});
const userPhoneNumber = {
number: "***********",
};
/***/
},
/***/ "./src/userService2.js":
/*!*****************************!*\
!*** ./src/userService2.js ***!
\*****************************/
/***/ (
__unused_webpack_module,
__webpack_exports__,
__vite_rsc_require__
) => {
"use strict";
__vite_rsc_require__.r(__webpack_exports__);
/* harmony export */ __vite_rsc_require__.d(__webpack_exports__, {
/* harmony export */ logUserPhoneNumber: () =>
/* binding */ logUserPhoneNumber,
/* harmony export */
});
/* harmony import */ var user_library__WEBPACK_IMPORTED_MODULE_0__ = __vite_rsc_require__(
/*! user-library */ "./node_modules/user-library/dist/userPhoneNumber.js"
);
const logUserPhoneNumber = () => {
console.log(
user_library__WEBPACK_IMPORTED_MODULE_0__.userPhoneNumber
);
};
/***/
},
},
]);src_userService1_js.main.js 也和上面类似,仅仅包含了我们库里的 userAccount 模块。
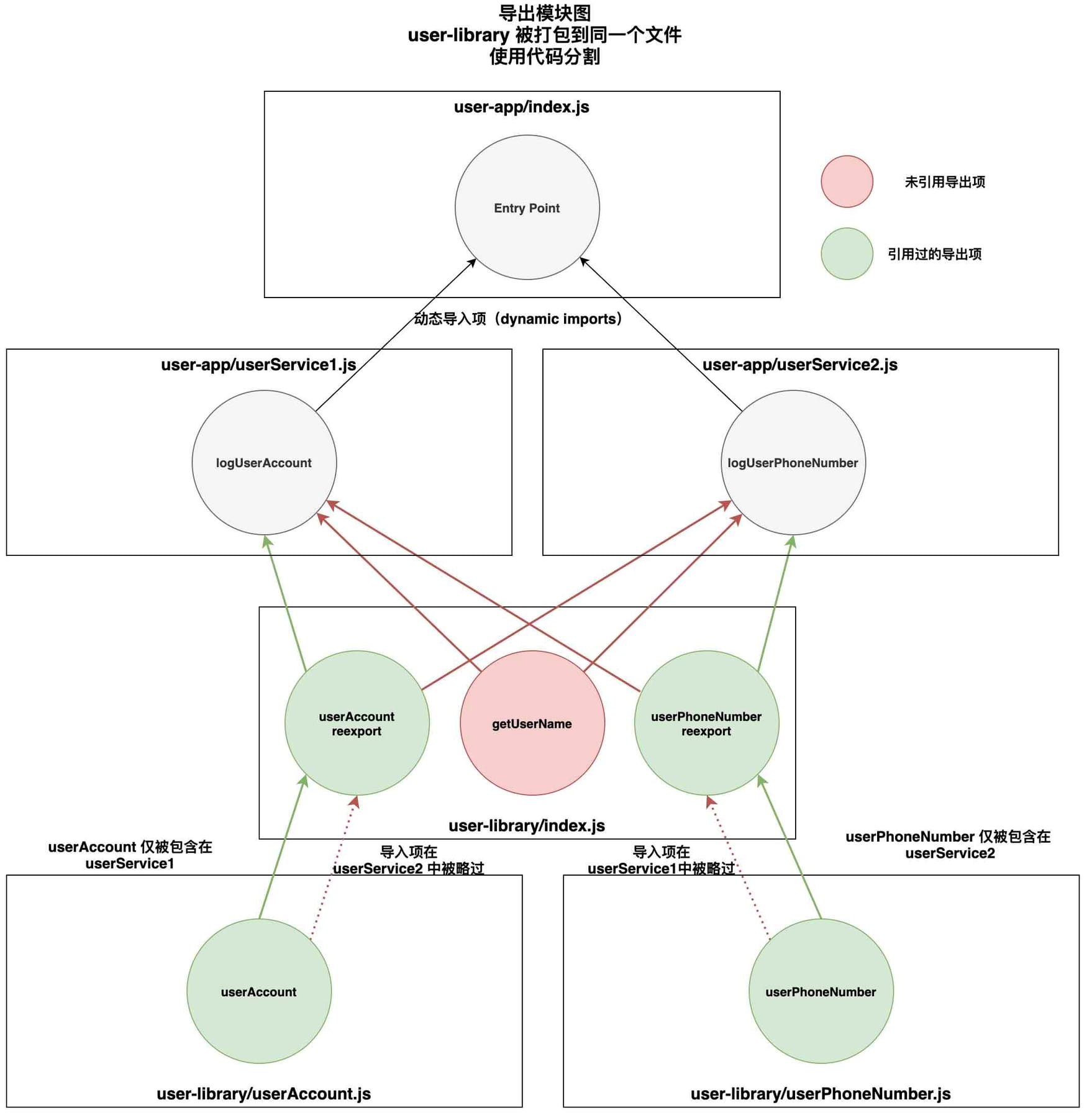
保留模块树可以让 Webpack 独立地对分割的 chunk 进行摇树优化
在上图中我们看到,userAccount 和 userPhoneNumber 仍然被识别为被引用的导出项,毕竟它们都在应用里被引用了至少一次。不过,这一次副作用优化让 Webpack 得以略过 userAccount 模块,因为它从未被 userService2 所导入。同样的事情也发生在了 userPhoneNumber 和 userService1 之间。
我们现在理解了:保留库中原始的模块结构是很重要的。不过,如果原始模块结构里只有一个模块,比如 index.js 文件,并且其中包含着所有的代码的话,那么保留这种模块结构是毫无用处的。要打造一个对摇树优化有着良好适配的库,我们必须将库的代码划分到若干个小的模块中,同时每个模块负责我们代码逻辑的一部分。
如果要使用“树”的比喻,我们需要将树上每片叶子视为一个模块。更小、更弱的叶子在树被摇动的时候更容易掉落!如果树上的叶子更少、更强,那么摇树的结果可能就不一样了。
本部分的总结如下:
- 为了能够充分利用副作用优化,我们应该保留库的模块结构。
- 库应该被划分为多个小的模块,每个模块仅导出整个库的代码逻辑的一小部分。
- 只有在副作用优化的帮助下,我们在应用里才能对引用的库进行摇树优化。
在转译库代码时不要丢失模块树以及 ES 模块的特征
**打包工具并不是唯一能够影响你的库被摇树优化的东西。**转译工具也会对摇树优化造成负面影响,因为它们会移除 ES 模块,或者丢失模块树。
转译工具的目的之一是让你的代码能够在那些不支持 ES 模块的浏览器中工作。不过,我们也需要记住:我们的库并不总会直接地被浏览器所加载,而是会被应用所导入。所以,鉴于以下两条理由,我们不能针对特定浏览器来转译我们的库代码:
- 在编写库代码的时候,我们并不知道我们的库会被用到哪些浏览器里,只有使用库的应用才知道。
- 转译我们的库代码会让它们变得不可被摇树优化。
如果你的库由于某些原因确实需要被转译,那么你需要保证转译工具不会移除 ES 模块的语法,以及不会移除原本的模块结构,原因正如前文所述。
据我所知,有两个转译工具会移除掉上述的两个内容。
Babel
Babel 能够使用 Babel preset-env 来让你的代码兼容指定的目标浏览器(target browsers)。这个插件默认会将库代码里的 ES 模块移除。为了避免它的发生,我们需要把 modules 选项设为 false:
module.exports = {
env: {
esm: {
presets: [
[
"@babel/preset-env",
{
modules: false,
},
],
],
},
},
};TypeScript
在编译你的代码时,TypeScript 会根据 tsconfig.json 文件里的 target 和 module 选项来转换你的模块。
为了避免它的发生,我们要将 target 和 module 选项设置到至少 ES2015 或 ES6。
此部分的总结如下:
- 确保你的转译工具和编译器不会将库代码里的 ES 模块语法移除。
- 如果需要检查上述问题是否存在,可以查看库的转译/编译产物里有没有 ES 模块的导入语法。
使用最新版的可进行摇树优化的打包工具
JavaScript 的摇树优化在 Rollup 的带动下流行了起来。Webpack 自从 v2 以来就支持了摇树优化。各打包工具都在摇树优化上做得越来越好。
还记得我们在上文讲到的 innerGraph 优化吗?它能够让 Webpack 将模块的导出项和其他模块的导入项关联起来。这项优化是在 Webpack 5 中被引入的。我们在本文里虽然一直在使用 Webpack 5,不过还是有必要认识到这项优化改变了整个业界。它能够让 Webpack 递归地寻找未被使用的导出项!
为了展示它到底是怎么做的,考虑 user-library 中的 index.js 文件:
import { userAccount } from "./userAccount";
const getUserAccount = () => {
return userAccount;
};
const getUserName = () => "John Doe";
export { getUserName, getUserAccount };我们的 user-app 仅使用了其中的 getUserName:
import { getUserName } from "user-library";
console.log(getUserName());现在,我们对比一下在有和没有 innerGraph 优化的情况下,打包输出有什么不同。注意,这里 usedExports 和 sideEffects 优化都是开启的。
没有 innerGraph 优化(比如使用 Webpack 4):
/*!*************************************************!*\
!*** ./node_modules/user-library/dist/index.js ***!
\*************************************************/
/*! exports provided: userAccount, userPhoneNumber, getUserName, getUserAccount */
/*! exports used: getUserName */
/***/ (function(module, __webpack_exports__, __vite_rsc_require__) {
"use strict";
/* harmony export (binding) */ __vite_rsc_require__.d(__webpack_exports__, "a", function() { return getUserName; });
/* unused harmony export getUserAccount */
/* harmony import */ var _userAccount_js__WEBPACK_IMPORTED_MODULE_0__ = __vite_rsc_require__(/*! ./userAccount.js */ "./node_modules/user-library/dist/userAccount.js");
const getUserAccount = () => {
return _userAccount_js__WEBPACK_IMPORTED_MODULE_0__[/* userAccount */ "a"]
};
const getUserName = () => 'John Doe';
/***/ }),
/***/ "./node_modules/user-library/dist/userAccount.js":
/*!*******************************************************!*\
!*** ./node_modules/user-library/dist/userAccount.js ***!
\*******************************************************/
/*! exports provided: userAccount */
/*! exports used: userAccount */
/***/ (function(module, __webpack_exports__, __vite_rsc_require__) {
"use strict";
/* harmony export (binding) */ __vite_rsc_require__.d(__webpack_exports__, "a", function() { return userAccount; });
const userAccount = {
name: 'user account'
};
/***/ }),有 innerGraph 优化(比如使用 Webpack 5):
/***/ "./node_modules/user-library/dist/index.js":
/*!*************************************************!*\
!*** ./node_modules/user-library/dist/index.js ***!
\*************************************************/
/***/ ((__unused_webpack_module, __webpack_exports__, __vite_rsc_require__) => {
/* harmony export */ __vite_rsc_require__.d(__webpack_exports__, {
/* harmony export */ "getUserName": () => (/* binding */ getUserName)
/* harmony export */ });
/* unused harmony export getUserAccount */
const getUserAccount = () => {
return userAccount
};
const getUserName = () => 'John Doe';
/***/ })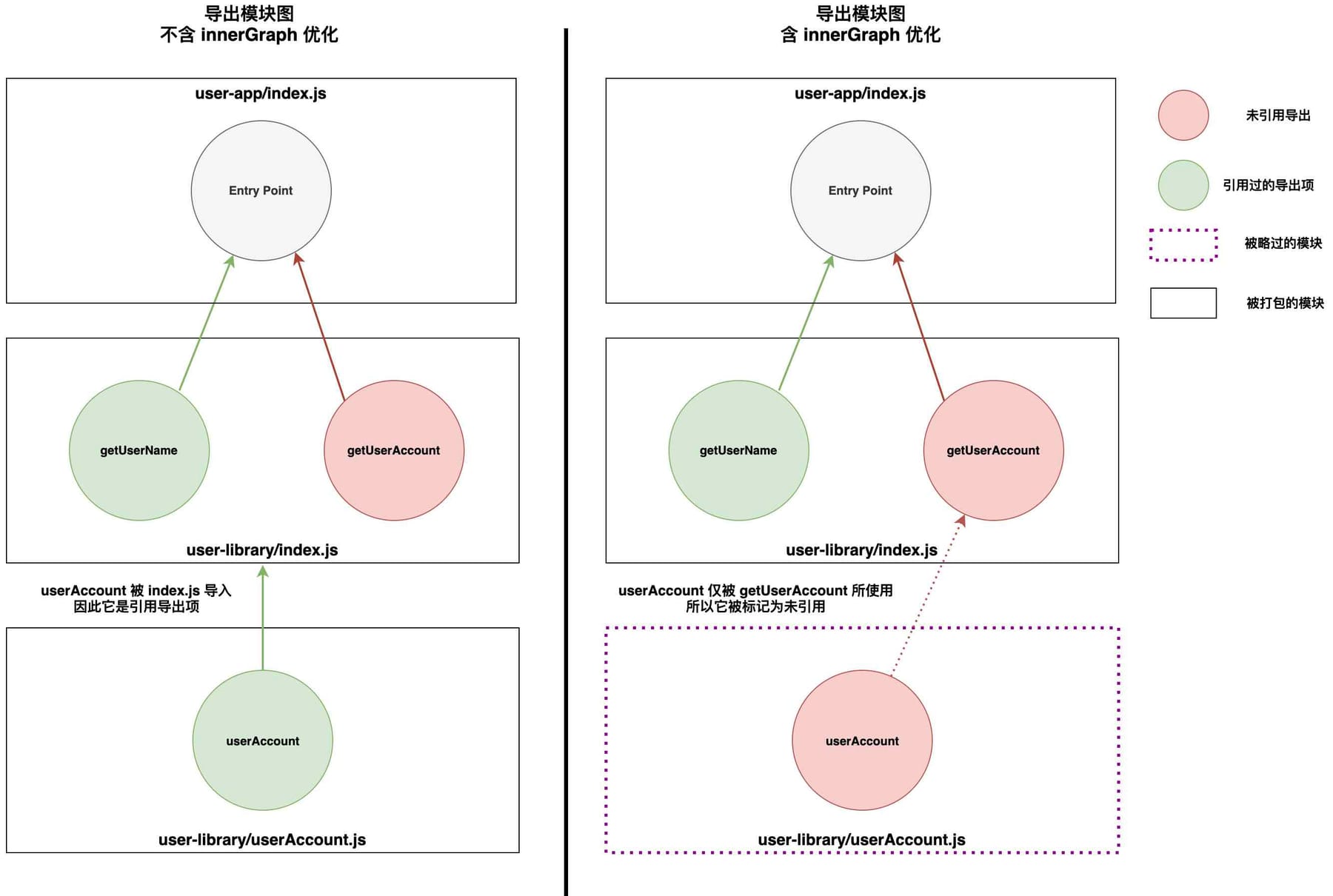
Webpack的 innerGraph 优化示例
Webpack 5 能够完全移除 userAccount 模块,但是 Webpack 4 不行,即使 getUserAccount 被标记为了未引用。这是因为 inngerGraph 优化的算法能够让 Webpack 5 将模块中未引用的导出项和它对应的导入项链接起来。在我们的例子里,userAccount 模块仅被 getUserAccount 函数所使用,因此可以被直接略过。
Webpack 4 则没有这项优化。开发者在使用这个版本的 Webpack 的时候因此应该提高警惕,限制单个源文件里的导出项数量。 如果一个源文件包含多个导出项,Webpack 会包含所有对应的导入项,即使对于真正被需要的导出项来说有些导入项是多余的。
总的来说,我们应该确保总是使用最新版的打包工具,这样我们就能从最新的摇树优化中获益。
总结
对一个库进行的摇树优化,并不是在配置文件里随便加一行来启用就能获得很好的效果。它的优化质量取决于多个因素,本文仅仅列出了其中的一小部分。不过,无论我们遇到的问题是什么,本文里做过的以下两件事情是对任何想要对库进行摇树优化的人很重要的:
- 为了确定我们库的摇树优化效果程度,我们需要在一个受控的环境下使用我们了解的打包工具来进行测试。
- 为了检查我们库的配置有没有问题,我们不仅仅是需要检查各种配置文件,还要检查打包输出。 我们在本文里一直都在对
user-library和user-app的例子做这种事情。
我真切地希望本文能够为你提供帮助,让你正在进行的构建拥优化程度最高的库的任务变得可能!
延申阅读
如果发现译文存在错误或其他需要改进的地方,欢迎到 掘金翻译计划 对译文进行修改并 PR,也可获得相应奖励积分。文章开头的 本文永久链接 即为本文在 GitHub 上的 MarkDown 链接。
掘金翻译计划 是一个翻译优质互联网技术文章的社区,文章来源为 掘金 上的英文分享文章。内容覆盖 Android、iOS、前端、后端、区块链、产品、设计、人工智能等领域,想要查看更多优质译文请持续关注 掘金翻译计划、官方微博、知乎专栏。